「熵」(Entropy) &「交差熵」(Cross-Entropy)
1102 機器學習
這篇文章是學習時整理的一些筆記,讓自己複習時方便,文章內容為閱讀清單內容之整理
「熵」是什麼?
Entropy 中文翻作「熵」,西元1854年由一位德國物理學家 Rodolph Clausius 提出,是一種對物理系統之無秩序或亂度的量度,早先應用於熱力學中,用來量度無法轉換成「功」的熱能。Claude Elwood Shannon在1948年將這概念引用到資訊領域來衡量接收到的資訊。reference
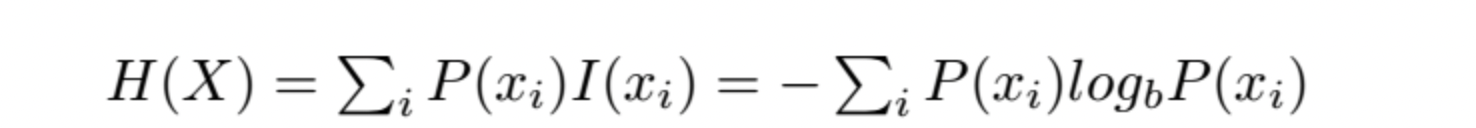
熵是服从某一特定概率分布事件的理论最小平均编码长度reference
在訊息論中,熵的概念最初是被運用在尋找一種高效且無損的編碼方式,以編碼的數據長度來決定「高效」,平均長度越短越高效,且同時還需要滿足「無損」的條件,也就是編碼後訊息不可以丟失。如果熵比較大,就代表這段訊息有比較多的可能狀態,且每個狀態的機率較低,若是有很長的訊息來了,就會難以確認它的狀態,有較大的不確定性。(若是想了解更多在訊息論中熵的計算建議前往閱讀清單第二則文章喔!)
舉個例子,若是天氣分佈機率如下圖,則某一事件概率分佈的平均最小編碼長度為下圖
| 編碼方式 | sunny(50%) | cloudy(25%) | rainy(12.5%) | snow(12.5%) | 編碼長度 |
|---|---|---|---|---|---|
| 方式一 | 10 | 110 | 0 | 111 | 20.5+30.25+10.125+30.125=2.25 |
| 方式二 | 0 | 110 | 10 | 111 | 10.5+30.25+20.125+30.125=1.875 |
| 方式三 | 0 | 10 | 110 | 111 | 10.5+20.25+30.125+30.125=1.75 |
出處
假设一个信息事件有8种可能的状态,且各状态等可能性,即可能性都是12.5%=1/8。我们需要多少位来编码8个值呢?1位可以编码2个值(0或1),2位可以编码2×2=4个值(00,01,10,11),则8个值需要3位,2×2×2=8(000,001,010,011,100,101,110,111)。
| A(12.5%) | B(12.5%) | C(12.5%) | D(12.5%) | E(12.5%) | F(12.5%) | G(12.5%) | H(12.5%) |
|---|---|---|---|---|---|---|---|
| 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
因此對於有j種可能狀態的訊息,每種狀態的機率為1/j,則該訊息所需的平均最小編碼長度為: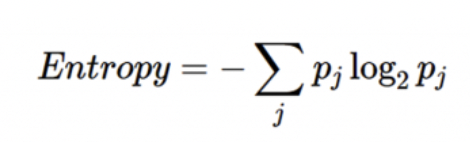
在機器學習中,若是一件事物發生的機率越小,不確定性越高,則當這件事發生了,它所代表的訊息量就越多
「熵」是一種對物理系統之無秩序或亂度的量度;資訊與熵是互補的,資訊就是負熵
多舉幾個例子
下圖中p代表是的機率、q代表否的機率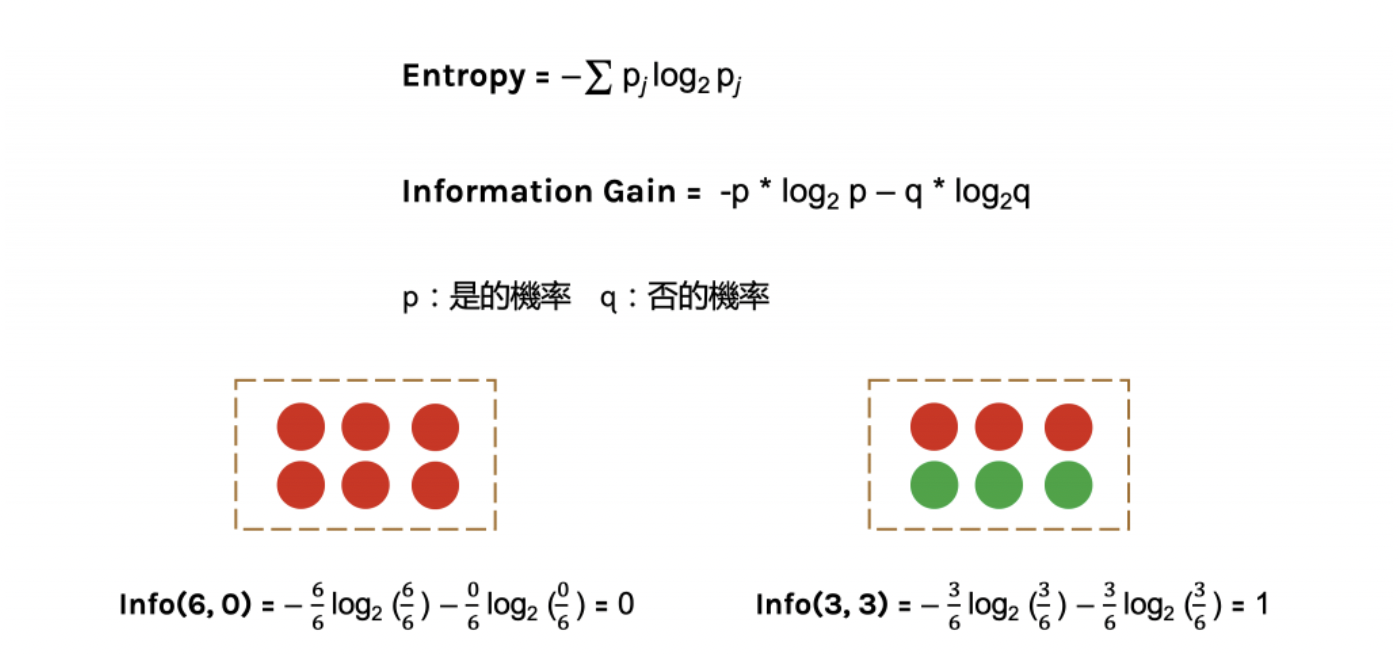
當資料被分類一致的時候entropy為0,當資料各為一半的時後為1
再舉一個例子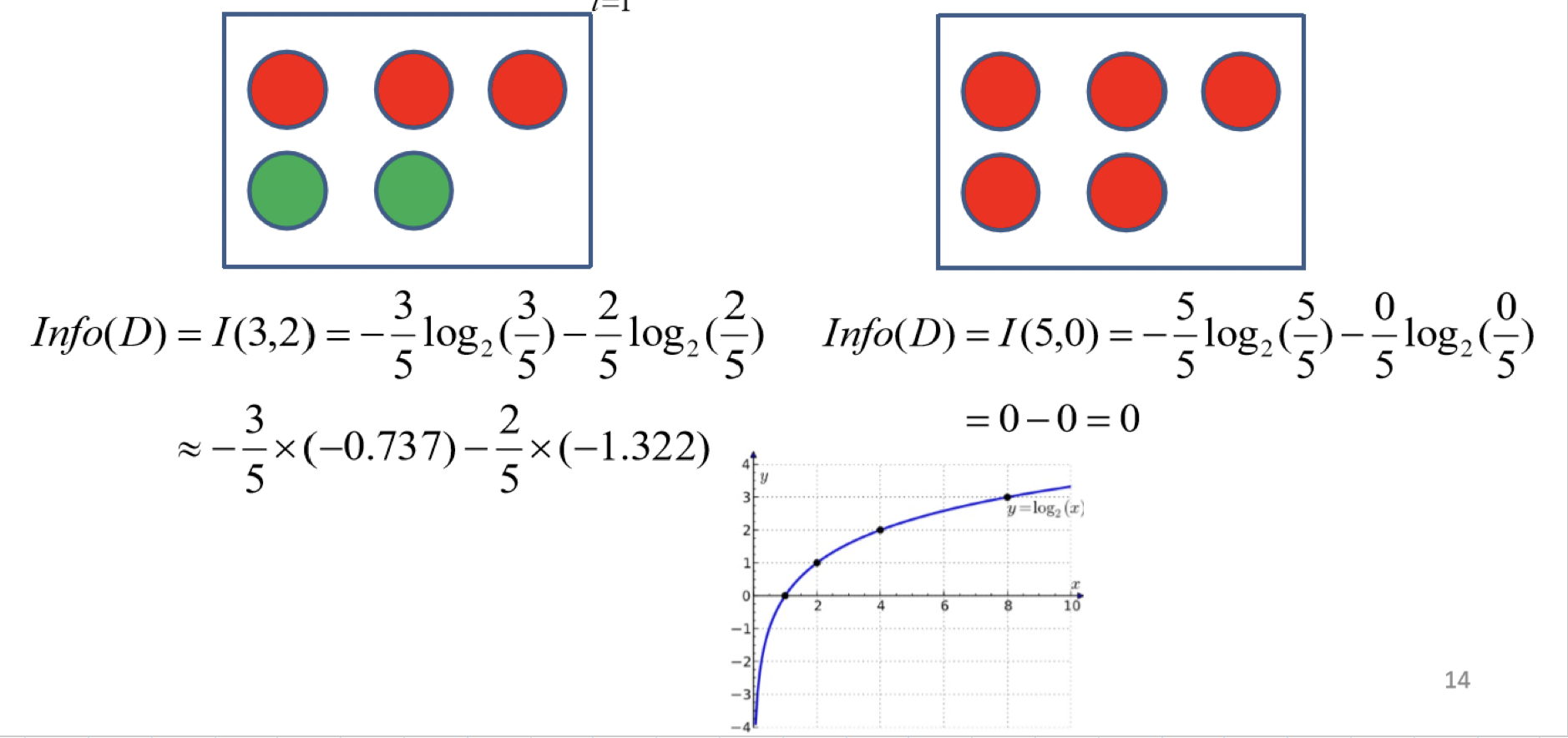
前面一直提到「機率」,那若是不知道事件的機率分佈,就是對熵做一個估計 —> 交叉熵
「交叉熵」是什麼?
若是今天我們不知道真實天氣的機率分佈(P),我們只有預估的天氣分佈(Q),我們就可以計算估計的熵: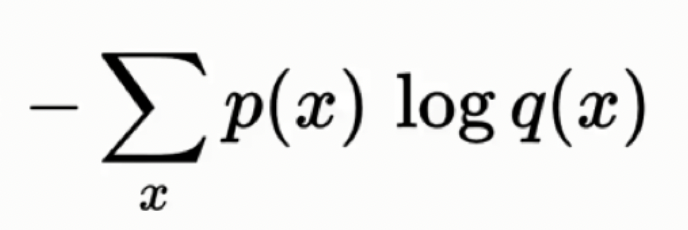
這個就是P,Q的交叉熵
在機器學習上可以解讀為:
「熵」與「交叉熵」
交叉熵使用H(P,Q)表示,意味着使用P计算期望,使用Q计算编码长度;所以H(P,Q)并不一定等于H(Q,P),除了在P=Q的情况下,H(P,Q) = H(Q,P) = H(P)。reference
有一点很微妙但很重要:对于期望,我们使用真实概率分布P来计算;对于编码长度,我们使用假设的概率分布Q来计算,因为它是预估用于编码信息的。因为熵是理论上的平均最小编码长度,所以交叉熵只可能大于等于熵。换句话说,如果我们的估计是完美的,即Q=P,那么有H(P,Q) = H(P),否则,H(P,Q) > H(P)。reference
更多交叉熵舉例👉https://zhuanlan.zhihu.com/p/149186719