Clustering 文章筆記整理 - ft. k-means, k-medioids, hierarchical clustering, density based clustering(DBSCAN)
1102 機器學習
這篇文章是學習時整理的一些筆記,讓自己複習時方便,文章內容為上課之內容及閱讀清單之整理
分群/聚類
分群是非監督學習的一種,數據不會被標註,主要目的在於找出輸入變數之間的關係,找出大致分布的趨勢,讓在同一個子集的資料都有一些相同的屬性
分群的方法
一般而言,分群法可以大致歸為兩大類:
1. 階層式分群法 (hierarchical clustering) : 群的數目可以由大變小(divisive hierarchical clustering),或是由小變大(agglomerative hierarchical clustering),來進群聚的合併或分裂,最後再選取最佳的群的數目。如:Agglomerative hierarchical clustering, divisive hierarchical clustering
2. 分割式分群法 (partitional clustering) : 先指定群的數目後,再用一套疊代的數學運算法,找出最佳的分群方式以及相關的群中心。如:K-means, K-medoid
reference
K-means
在資料中,將資料分成K堆(K是自定義的),透過反覆檢閱資料來不斷更新群中心
Steps of K-means
目的k個聚類,使其滿足最小square-error
- given n objects, initialize k cluster centers
- assign each object to its closet cluster center
- update the center for each cluster
- repeat 2 and 3 until no change in each cluster center
Distance measure method
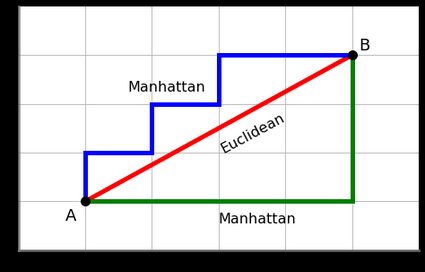
Euclidean distance measure
兩點間的直線距離Cosine distance measure
找兩向量之間的cosineManhattan distance measure
兩點間在座標系統上的絕對軸距總和
如下圖綠線(藍線為等價的曼哈頓距離)
Drawback of K-means
- the parameter of k-means:
- must decide the number of cluster in advance
- different initial center will result in different cluster result
- the center of k-means can be virtual node
- k-means cannot deal with category data
- k-means is heavily affect by noise –> k-medoid
K-medoid
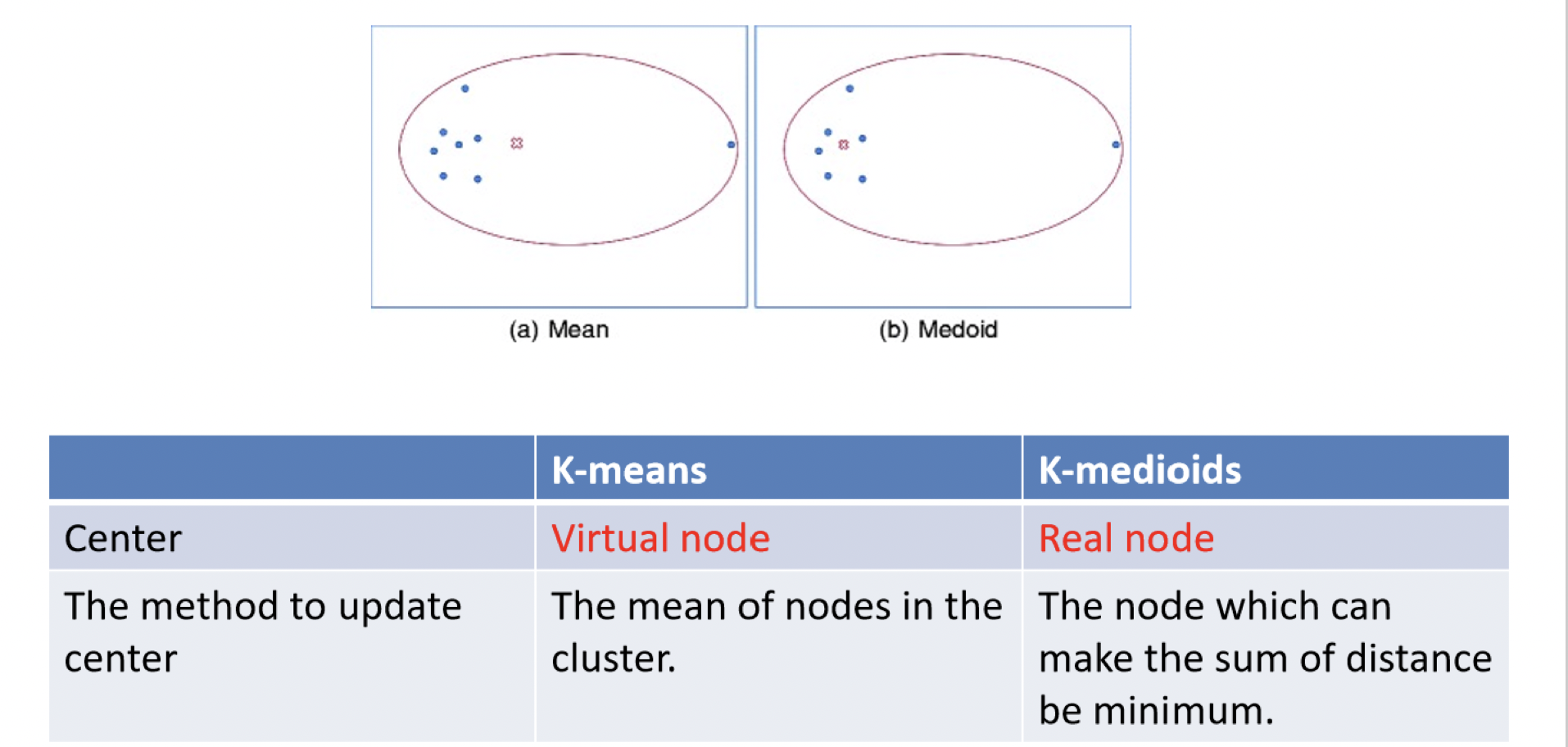
和k-means的運作方式很像,不過因為k-mean決定中心點距離是以平均,導致容易受極端資料的影響,且中心點不一定是實體點,故k-medoid做了一點升級,它採用中心點的方式為計算群內距離和最小的方式(可以想像是中位數),這樣不容易受極端值的影響,且除了可以處理數值型資料,也可以處理類別型資料~
然而,從運作過程中我們也可以看出,相對K-means來說,K-medoids的計算量是非常龐大的!每一次的中心點移動,都需較再計算兩兩樣本之間的距離以及總和,尤其在面對龐大資料量的時候,會消耗相當大的記憶體。因此,相較於K-medoids,K-means在速度上具有強大的優勢,並且適用於龐大的資料量,而K-medoids僅適用於小量資料。reference
K-means vs K-medoid
Hierarchical Clustering
階層式分層法是透過一種階層式的架構,將資料層層反覆分裂或聚合,最後產生樹狀結構常見的方式有Agglomerative和Divisive兩種
Agglomerative hierarchical clustering
是一個由下而上的方法,採用聚合的方式,將資料逐漸的合併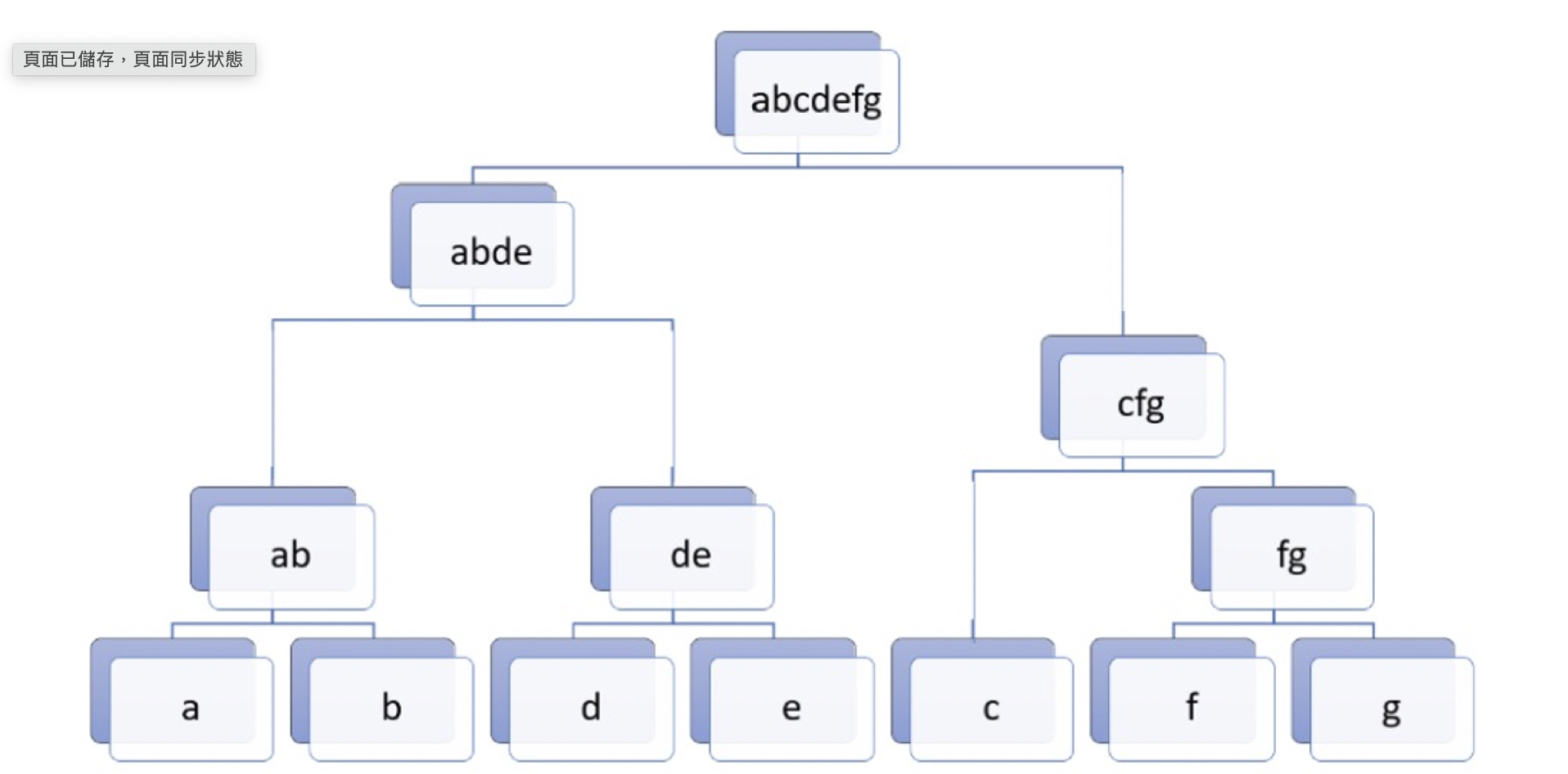
Steps of agglomerative
- every node is a cluster
- scan all the nodes, choose two nodes which are closet to be a cluster
- repeat 2, 3 untill all data becomes a cluster or achieve the x cluster
Distance of two cluster
- Single-linkage agglomerative algorithm 單一連結聚合演算法
群間的距離定義為兩群中最近點的距離 - Complete-linkage agglomerative algorithm 完整連結聚合演算法
群間的距離定義為兩群中最遠點間的距離 - Average-linkage agglomerative algorithm 平均連結聚合演算法
群間的距離定義為兩群間各點間的距離總和平均 - Centroid method 中心聚合演算法
群間的距離定義為兩群中心點間的距離 - Ward’s method 沃德法
群間的距離定義為兩群合併後,各點到合併群中心的距離平方和
Drawback of hierarchical clustering
- define the distance measure of two clusters
- define the number of cluster
- suitable for biological clustering
- hierarchical clustering needs much computation resource since the method has to scan every data in each iteration
Divisive hierarchical clustering
是一個由上而下的方法,採用分裂的方式,將資料逐漸的分裂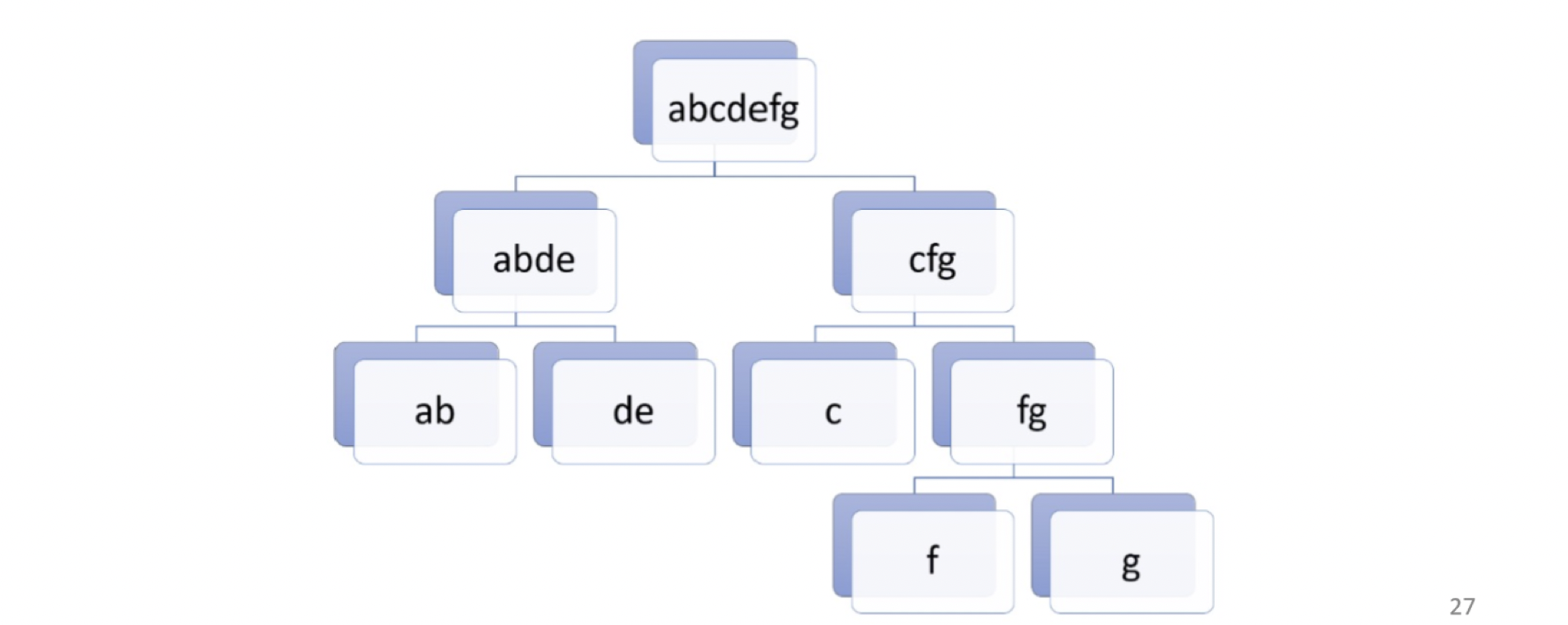
Density Based Clustering (DBSCAN)
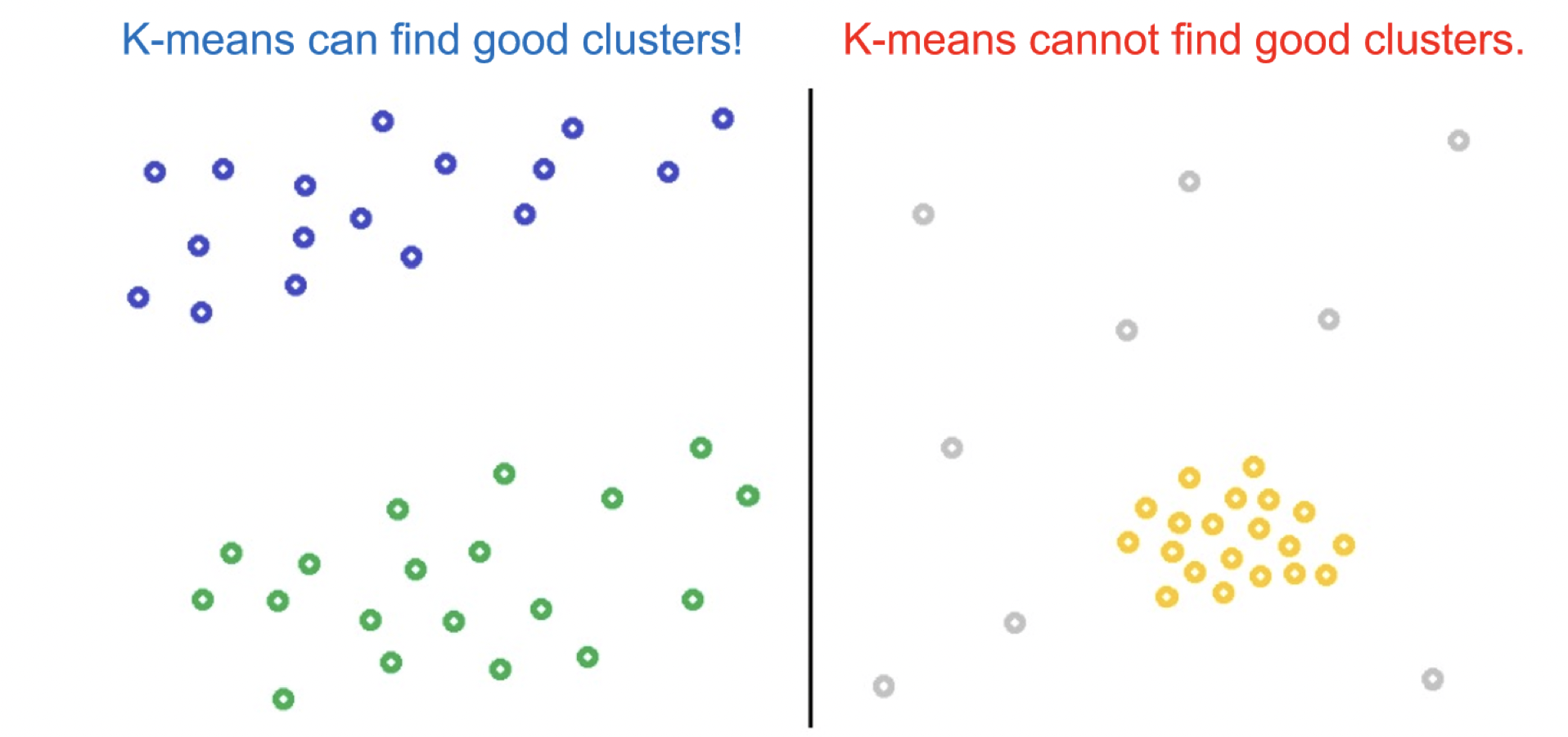
如上圖,若是我們以k-means來分群左邊的資料,則得到的結果或許還不錯,但若是拿來分群右邊的資料,結果就不會太好,這時候我們就可以用DBSCAN來分群
DBSCAN是一個基於密度來分群的算法,他會依據資料點在特徵空間中的密度來進行分群
在開始分群之前我們需要先定義兩個參數:
- R(radius of neighborhood): radius that if includes enough number of point within, we call it a dense area
- M(min number of neighbor): the minimum number of data points we want in a neighborhood to define a cluster
為了更好理解,我們用下面那張圖來說明
在範圍R內需有M個鄰居(也就是資料點)才會構成高密度區域
每個資料點在演算法中會有以下其中一種身份:
- Core point: within R neighborhooh of the point, there are at least M points
- Border point: its neighborhood contains at least M data points or it is reachable(it’s within R distance from the core point) from some core points
- Outlier point: not a core point nor a border point
Steps of DBSCAN
- label points
- connect core points that are neighbors and put them in the same cluster(cluster is formed by at least one core point and all reachable border points)
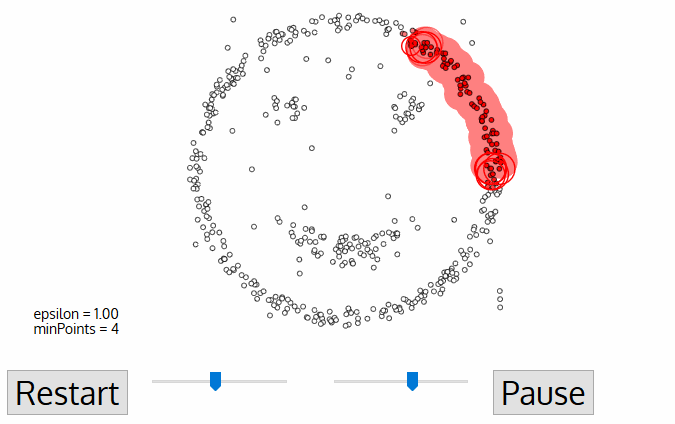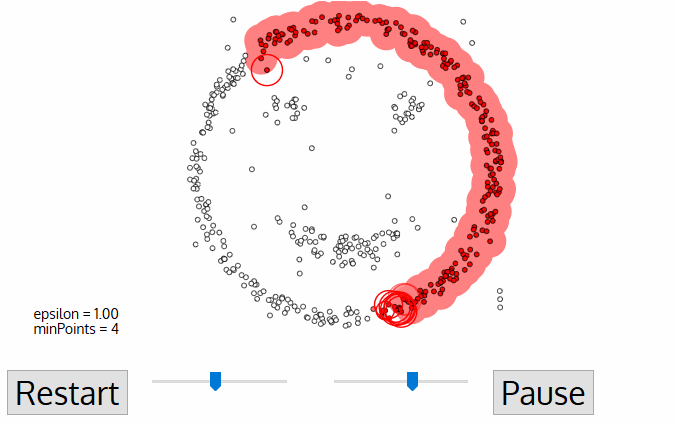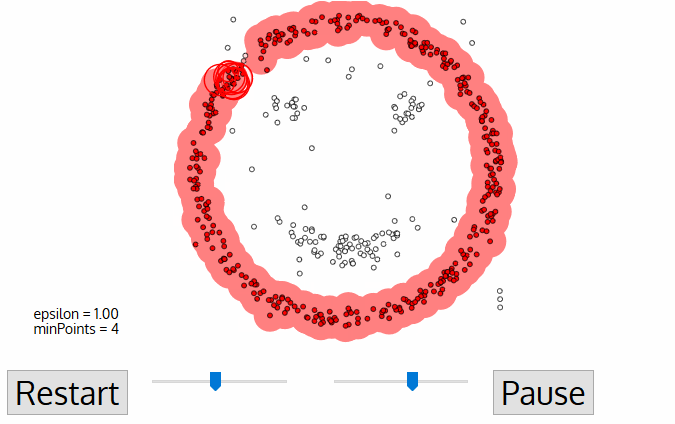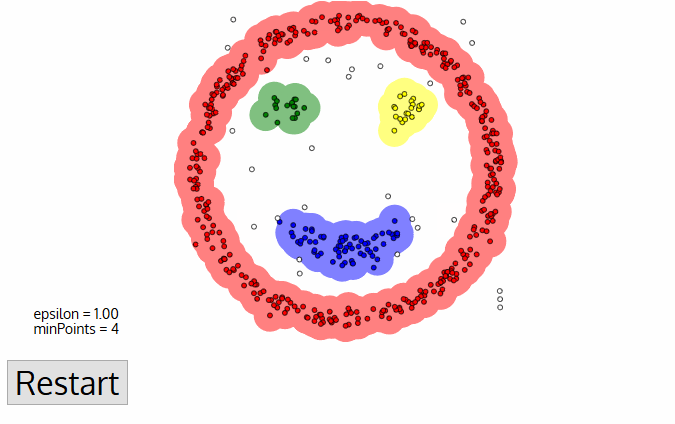
Advantages of DBSCAN
- 聚類速度快且能夠有效處理噪聲點和發現任意形狀的空間聚類
- 與K-MEANS比較起來,不需要輸入要劃分的聚類個數
- 聚類簇的形狀沒有偏倚
- 可以在需要時輸入過濾噪聲的引數
閱讀清單

Whether u have any question or not, feel free to send messages to me <3
Welcome to Isadora's blog, wish u a nice day.