Convolution Neural Network 筆記文章整理
1102 機器學習
二更 (初更為2021/10/26
這篇文章是學習時整理的一些筆記,讓自己複習時方便,文章內容為上課之內容及閱讀清單之整理
History
在開始之前先來大致看過CNN的歷史吧!
1960
美國兩位生物學家Hubel、Wiesel在研究貓腦皮層時,發現局部敏感和方向選擇的神經元,具有其獨特的網絡結構可以有效地降低反饋神經網絡的複雜性。
1980
KunihikoFukushima提出了CNN的前身 —— neocognitron
2000s
LeCunetal等人發表論文,確立了CNN的現代結構,後來又對其進行完善。
–他們設計了一種多層的人工神經網路,取名叫做LeNet-5 ,可以對手寫數字做分類。和其他神經網路一樣,LeNet-5 也能使用 backpropagation 演算法訓練。
DNN to CNN
DNN在影像訓練上時存在著部分問題:
若是我們使用DNN來訓練影像,我們都知道一張圖片會有3個chanel,因此我們在訓練時會將這整張圖片拉成一個很長的vector,若是圖片為100100,則這個vector就會是100100*3維的,再將這個喂進我們的網路訓練,不過因為DNN是採用全連接層,需要的參數會非常龐大,也容易造成局部最優
若是我們將整張照片放入DNN訓練,效率會非常不好,若想詳看驗證可以前往這裡
不過其實我們慢慢發現我們在訓練影像時,不需要一次直接判斷整張影像,舉例來說:
當你在找鳥類時,你不會需要看到一整隻鳥,你可能只需要看到鳥嘴,你就可以知道你找到鳥類了,機器也是如此
我們可以透過一個一個小區域來觀察,這就是卷積的概念,每次只看一個小區域,看完那個小區域的時候就再往下一個小區域移動,至於區域大小要如何,也是取決於個人網路的設計
CNN是透過卷積核作為中介來操作,因此更適合做為影像辨識
- Some patterns are much smaller than the whole image
- Connecting to small region with less parameters
- The same patterns appear in different regions
- Subsampling the pixels will not change the object, we can subsample the pixels to make image smaller -> Less parameters for the network to process the image
Pixels in Image
- Each image contain many pixels.
- Each pixels compose 3 channels – red, green, blue (RGB).
- Each channel have brightness levels between 0~255.
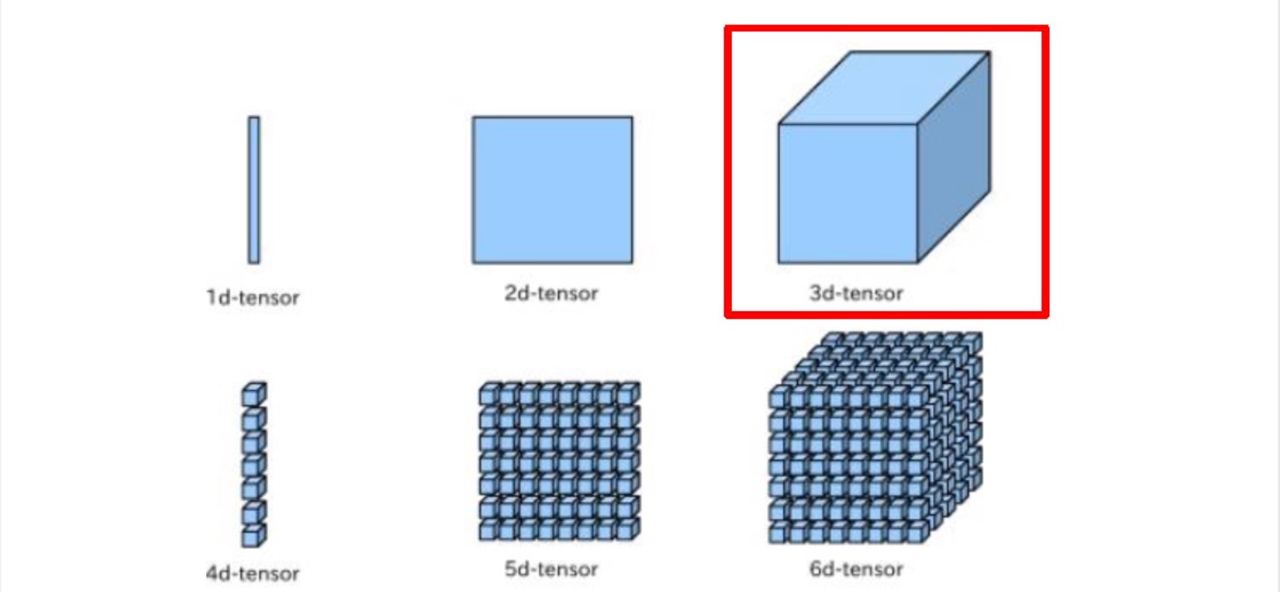
A image is a 3D-tensor –> Input many images into a batch => Becomes a 4D-tensor
Convolution Neural Network
卷積概念圖
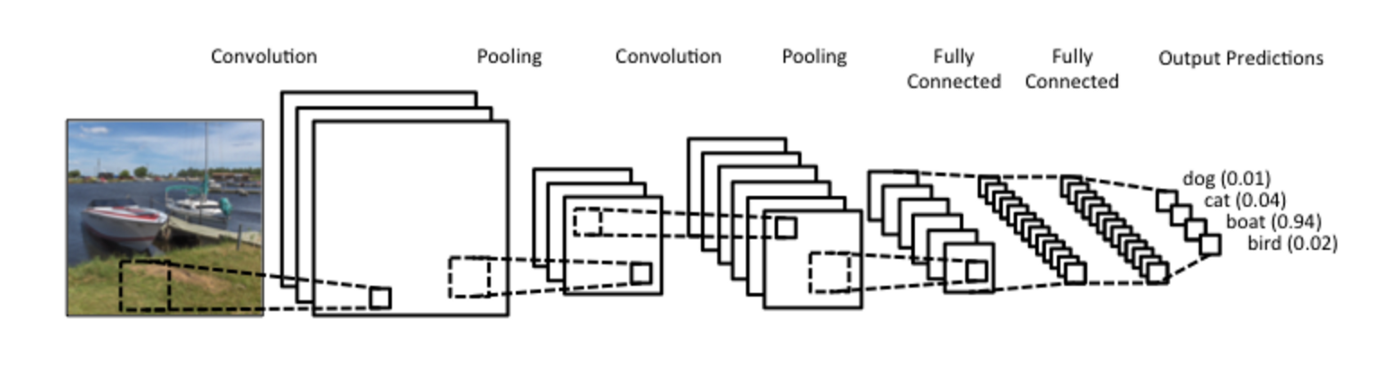
簡單來說,圖片不斷經過 Convolution, Pooling,flattern後再加上 Fully Connected 就是 CNN 的架構了!
The important three components of CNN:
- Convolution: Extract some features on specific local area
- Pooling
- Fully Connected
Convolution(卷積)

一般如果在網路上google卷積是什麼的話你會看到上圖左邊的這個公式,而這個公式其實代表的就是“卷”跟”積“兩個字分別對應的意思
“卷”: 對g函數進行翻轉
“積”: 把g函數平移到n,這個位置對兩個函數的對應點相乘後相加
兩個函數的卷基本質上就是先將一個函數翻轉,然後進行滑動疊加
(疊加在連續是指對兩個函數乘積求積分,離散是指加權求和)
整體看來過程就是翻轉、滑動,疊加一直重複,多次滑動得到的一系列疊加構成卷積函數
雖然很複雜,但是如果用例子來看就會好懂一點~

如果以丟骰子來當例子解釋卷積,我們今天要求兩個骰子點數和為四的機率,有兩個函數f和g,f(1)是指第一個骰子出現點數一的機率,以此類推,g代表第二個骰子,那我們可以試著把它寫成卷積函數的形式
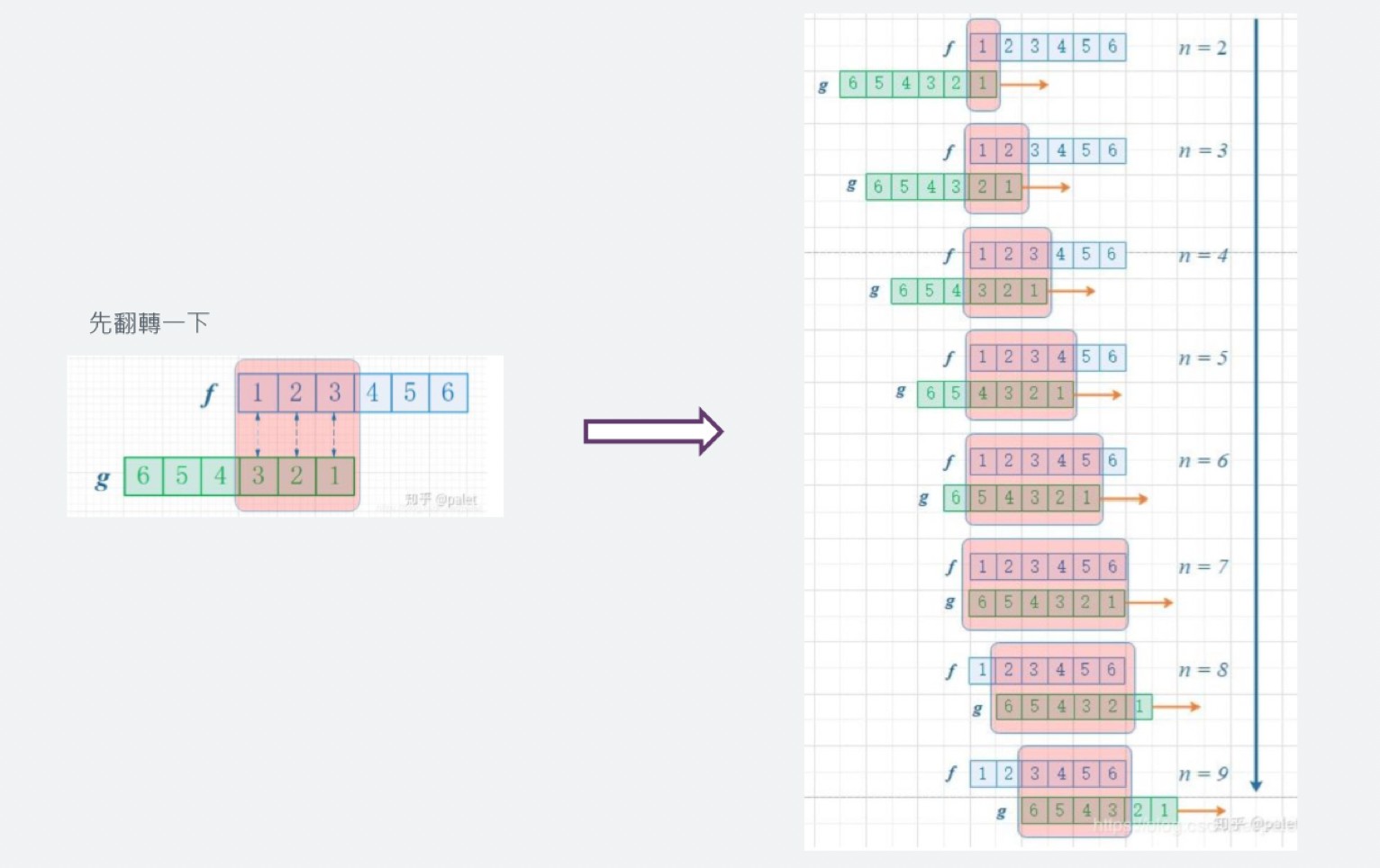
但為了方便,先將g翻轉一下,這樣就可以方便的去推斷骰子和為n的機率了
圖中若是每個點數出現的機率相同那我們就可以推斷出兩個骰子的點數和為七的機率最大
還有很多應用舉例,像是做饅頭,假設有一台作饅頭的機器會不斷的生產饅頭,設有一個f函數表示一天生產的饅頭總數,那把f積分起來就可以知道一段時間內生產的饅頭數
假設有一個函數g是紀錄一段時間內有幾個饅頭會壞掉,這樣透過這兩個函數的卷積我們就可以知道一天後饅頭會腐敗幾個,就可以去調整饅頭生產的速度,這是連續卷積的例子
卷積運用在影像處理的例子也是很常見的
舉一個最常接觸到的例子 - 修圖軟體,那些修圖軟體的銳化、浮雕之類的美術特效就是用卷積達成的
每張圖片都可以表示成由pixel組成的陣列,我們之所以可以對圖片作出不同效果是因為我們在對圖片作不同的卷積,我們會不斷的擷取對資料的特徵,再對特徵進行分類或是預估的動作

我們之所以可以做過出不同的美圖效果是在對圖片做不同的卷積(銳化和模糊或是邊緣增強等操作)
用銳化來舉例,銳化過後的圖片可以看出圖片裡面物件的”邊緣被強化”了,而”邊緣被強化”就是一個有效的特徵
所以不同的卷積就可以從圖片擷取出各種不同的特徵,像是”邊緣”、”曲線”等等的特徵,然後我們再去對特徵做選擇,並且利用特徵來做分類跟預估
這就是Convolution Neural Network的由來,對圖片去做擷取特徵的動作,找出最好的特徵最後再進行分類
卷積如何達成?
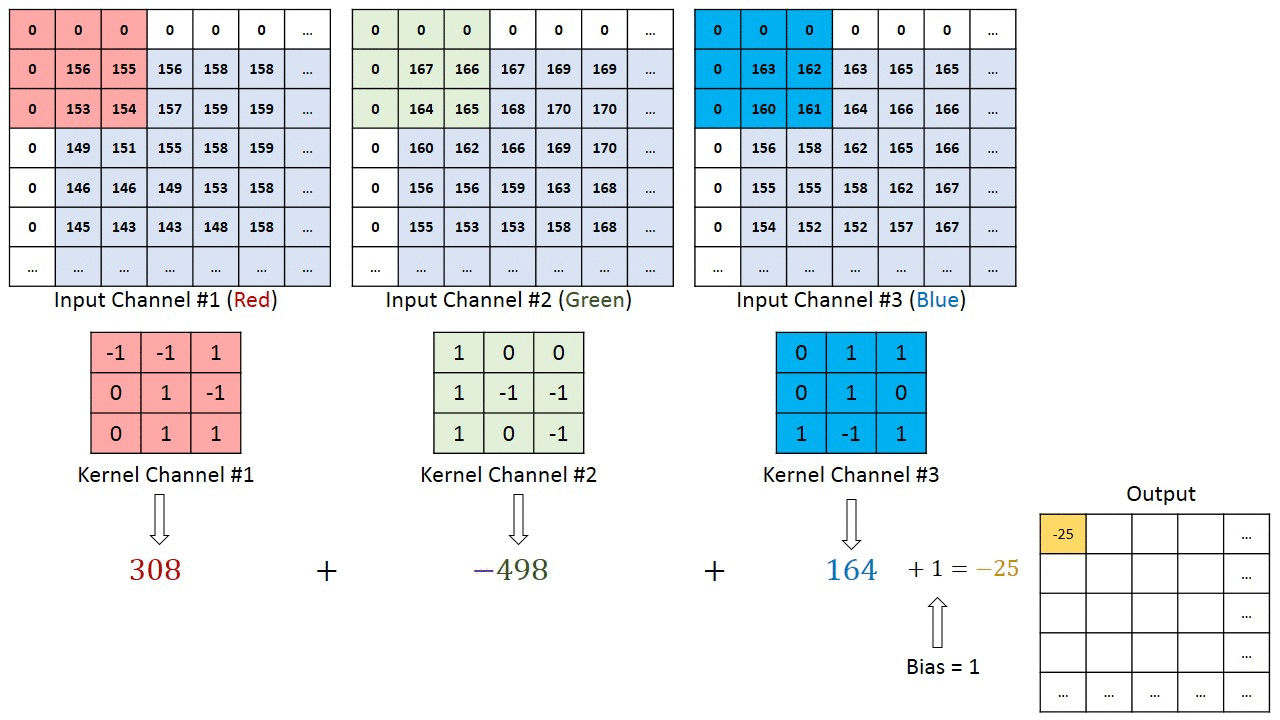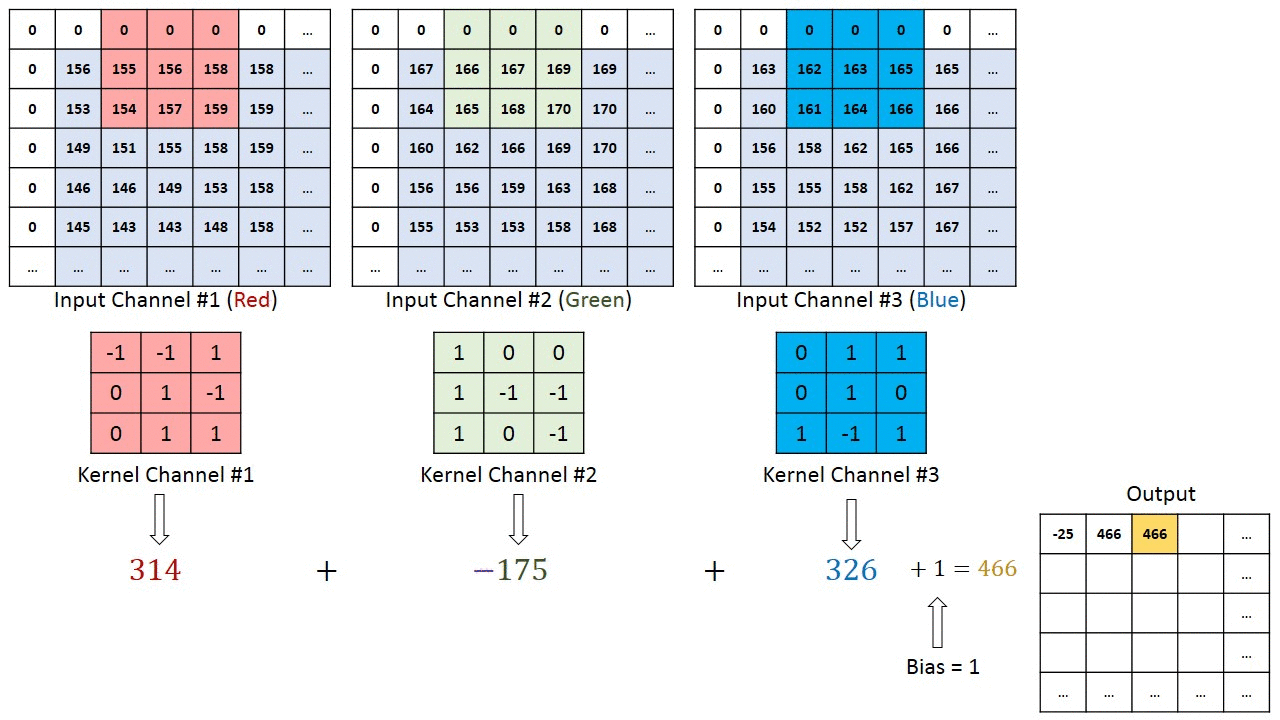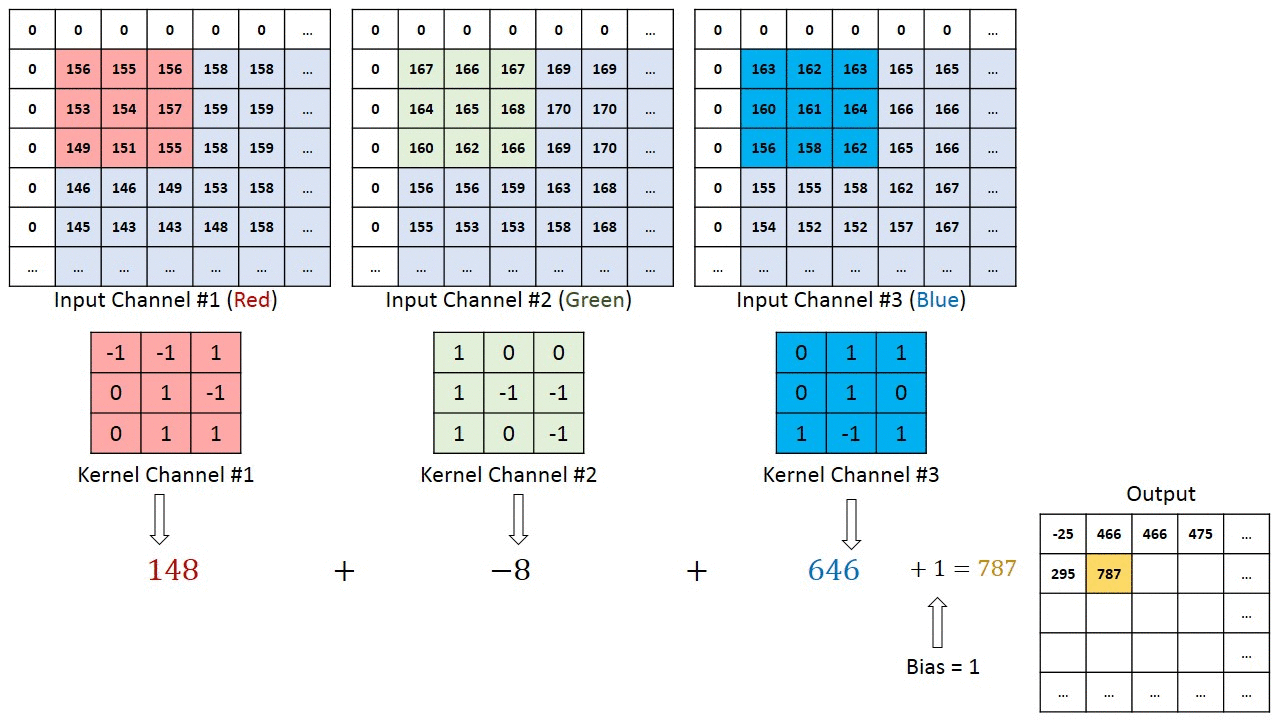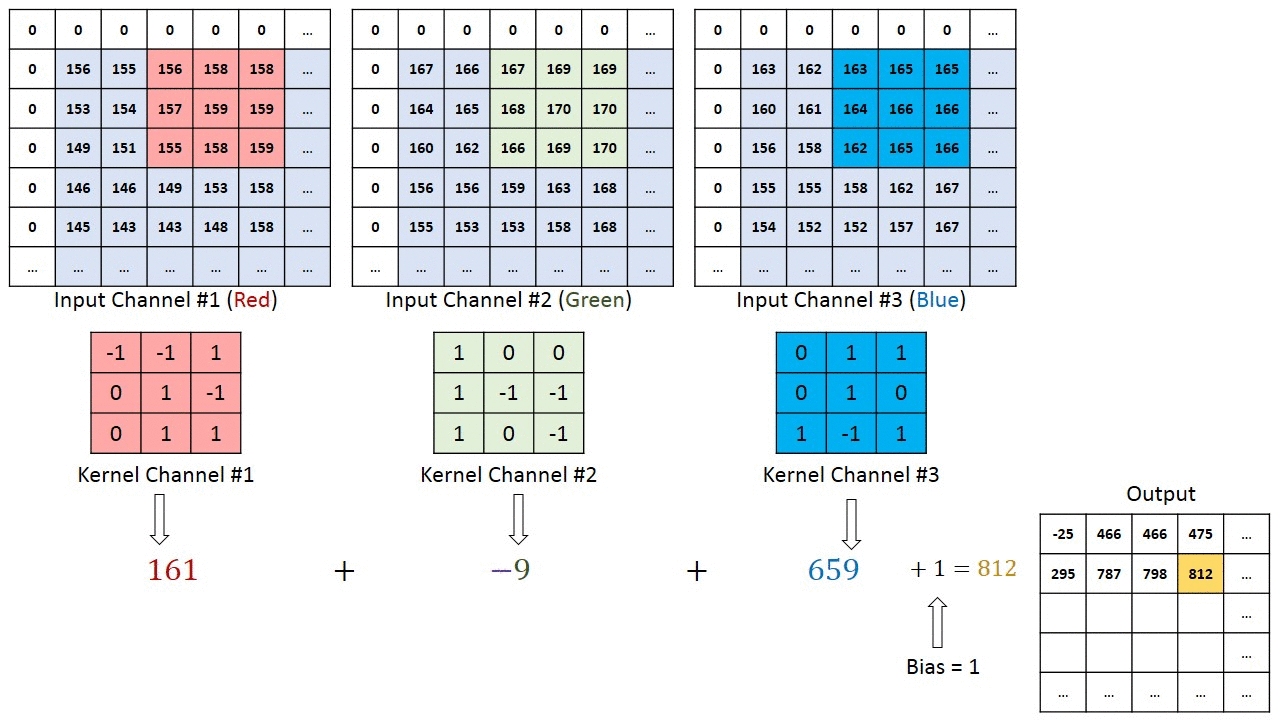
將3 X 3的矩陣在圖片pixel上一步步移動 (在卷積層中移動的步數稱為Stride步數)
在每個位置的時候,計算兩個矩陣相對元素的乘積並相加,輸出一個值然後放在一個矩陣(右邊粉色的矩陣),這就是基本的卷積運算
橘色矩陣就是所謂的”卷積核(Kernel)”,也稱作Filter,美圖也就是用不同的Kernel做卷積所達成的
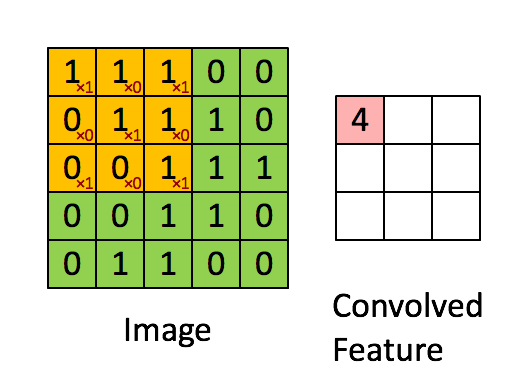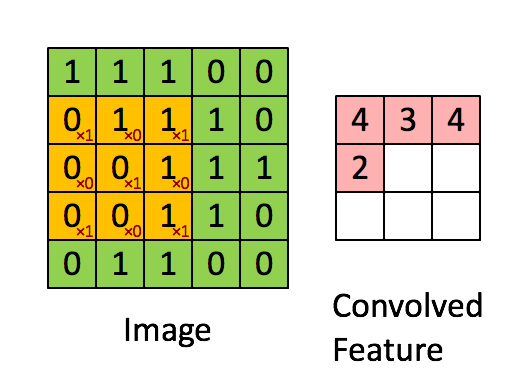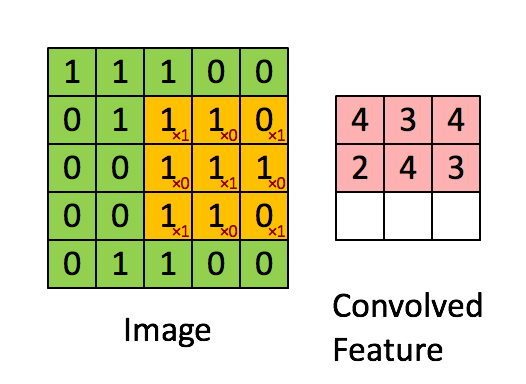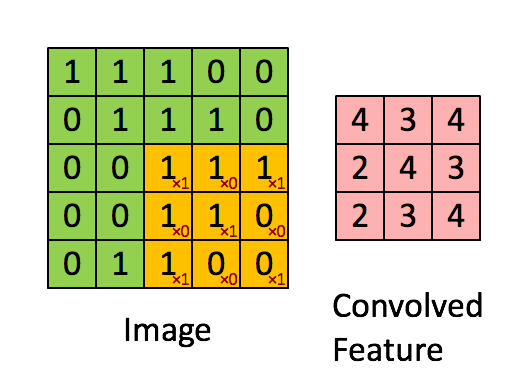
📌 Zero Padding:
每做一次卷積出來後的feature map會越來越小,則Zero Padding他可以將圖片向外擴張補0後再進行卷積,這樣卷積過後的特徵圖就會跟原本的圖一樣了
卷積參數
- Filter size: 卷積核的大小
- Stride: 卷積核在圖片上運算一次後的移動pixel步數
- Padding: 在feature map 外擴增0的圈數
- Padding zero on image boundary
- Remain the same size after convolution
卷積參數怎麼算
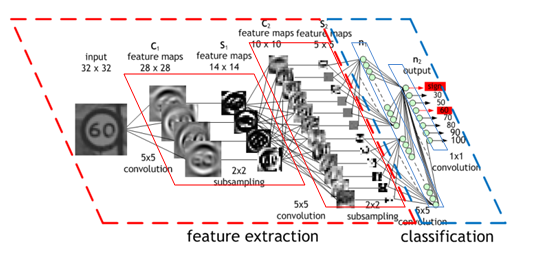
以下我們都用LeNet講解~
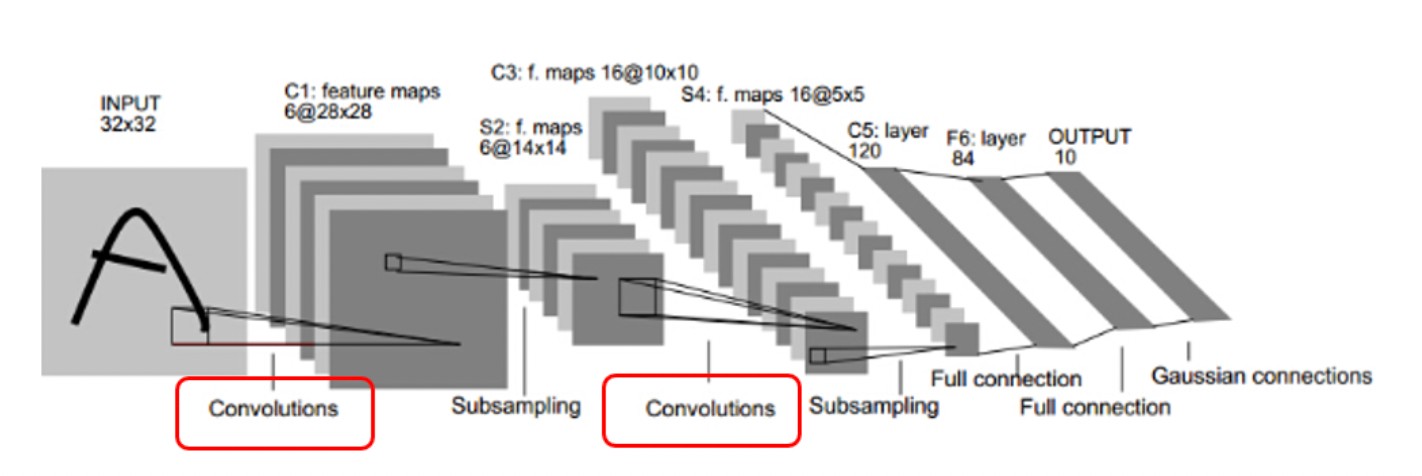
第一層的卷積層 Input 為 32 x 32 的 image,然而經過 Convolutions 的時候出現6張 28 X 28 的Feature map
Q1. 為什麼做完卷積後的每一個Feature map都是28X28呢?
3X3的卷積核對5X5的圖片出來的Feature map是3X3,因為卷積核由最左邊到最右邊只能走3步,這是步數為1的情況,那如果步數為2的情況呢?出來的Feature map是2X2,我們可以推測出一個公式
所以5X5的Kernel,步數為1的情況出來的Feature map 就是28X28(Input為32X32 沒有做Zero Padding的情況下)
Q2. 為什麼會出現6張Feature map呢?
答:用6個”不同的卷積核”去對Input做卷積
第一個卷積層出來後的feature map為 6張,因為卷積核數量為6
第二個卷積層出來後的feature map為16張,因為卷積核數量為16
Q3. 第二次的卷積層出來的深度怎麼不是6*16呢?
答:卷積核是可以有深度的(舉下面那張圖為例子,可以看作是深度為3的卷積核),因此第二個卷積層的卷積核就是16個深度為6的卷積核,所以出來的feature map深度就是16
(如果還是無法想像,可以把六張14x14的feature map視為是一張深度為6的照片,則經過16個不同的卷積後,出來的feature map深度為16)
Pooling(池化)
Pooling,也可以稱為Subsampling(采樣),目的是在將圖片資料量減少並保留重要資訊的方法,把原本的資料做一個最大化或是平均化的降維計算
Pooling常用的方式有三種,Max Pooling, Mean Pooling, Min Poling,池化層跟卷積層一樣,有個Kernel(大多為2X2),對卷積層出來的feature map做運算
通常會採用Max Pooling計算,好處是當圖片平移幾個Pixel對判斷上不會造成影響,有很好的抗雜訊功能
📌 Pooling 也可以做Padding讓圖片不要一次就變得太小
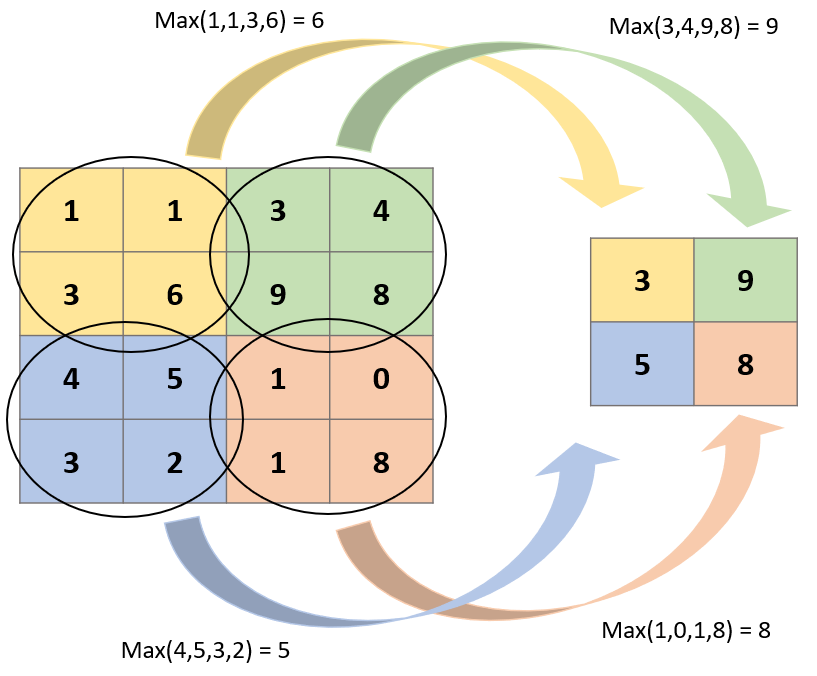
這張圖是利用2X2的Kernel 在image上用”步數”2(Stride)進行Pooling的基本運算,沒錯,就是很直觀也很簡單的,在Kernel經過的地方,取出最大值,就達成降維了。
為什麼要做池化層?
對特徵圖(Feature map)降維,並且保留重要的特徵,參數減少,可防止Overfitting。
越複雜或是參數越多的模型容易造成Overfitting,Pooling層有效降低我們的參數,而且還可以保留重要的特徵,也可以使模型對圖像微小的變換或是一些失真變得更沉穩(因為我們取了Kernel的最大值,微小的失真並不會改變結果,最大值還是最大值)。more卷積跟Pooling後可對”微小”的變化保持不變性(invariance), 旋轉、平移、伸縮等的不變性。
more
Fully Connected Layer(全連接層)
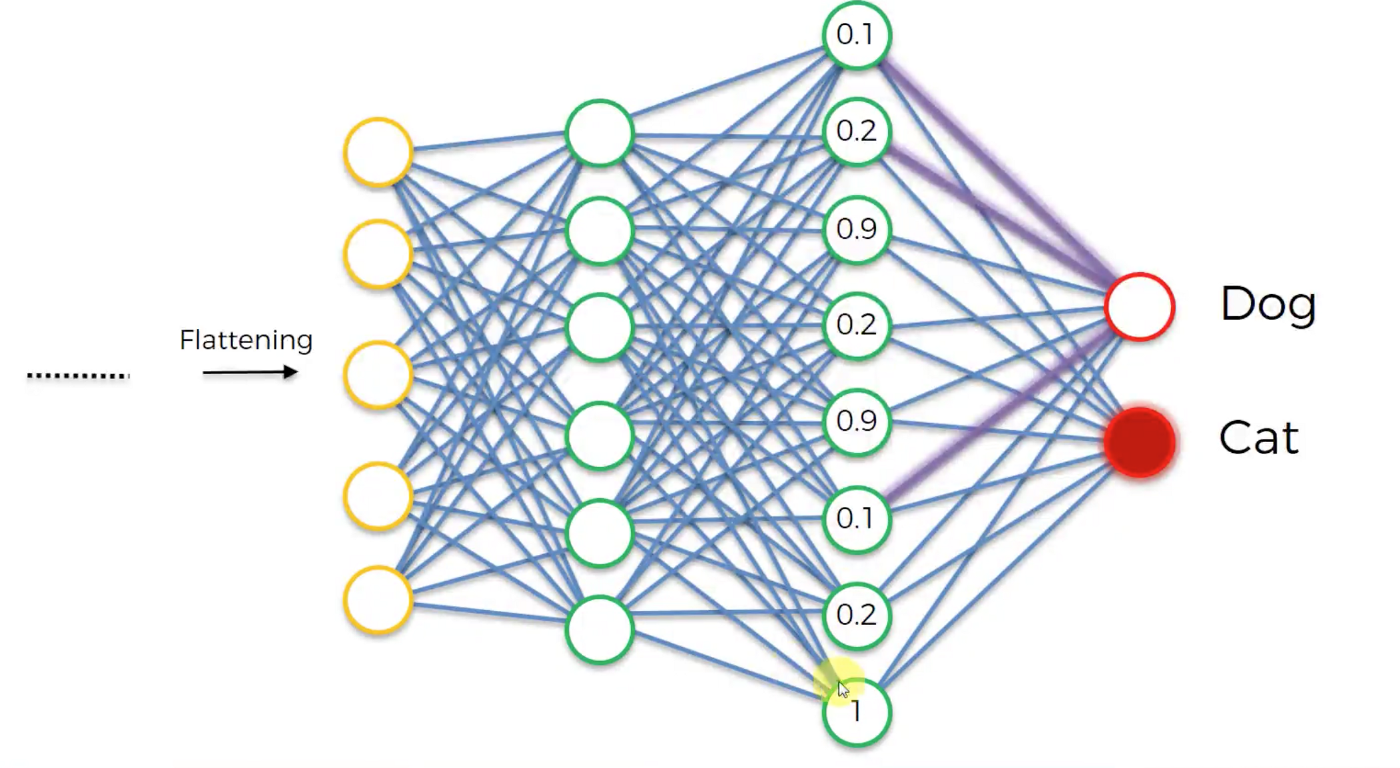
基本上全連接層的部分就是將之前的結果平坦化之後接到最基本的神經網絡了,因為做完前面的作業後輸出還是一張圖像,因此我們需要將他flattern後再接上NN,就可以分類了
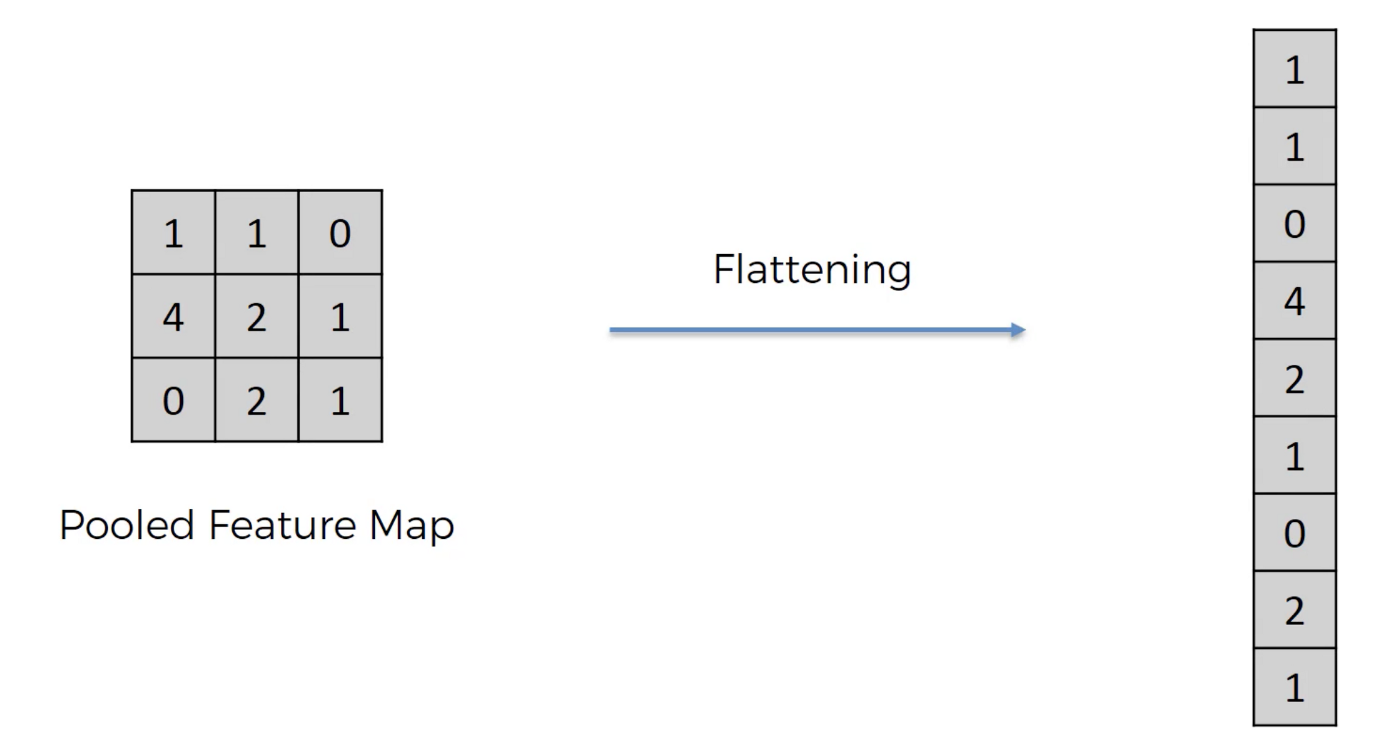
Summary
CNN的重點之一在於權重共享,當我們進行卷積滑動時, 代表我們是用同一種權重在作業,也表示權重是不會變動的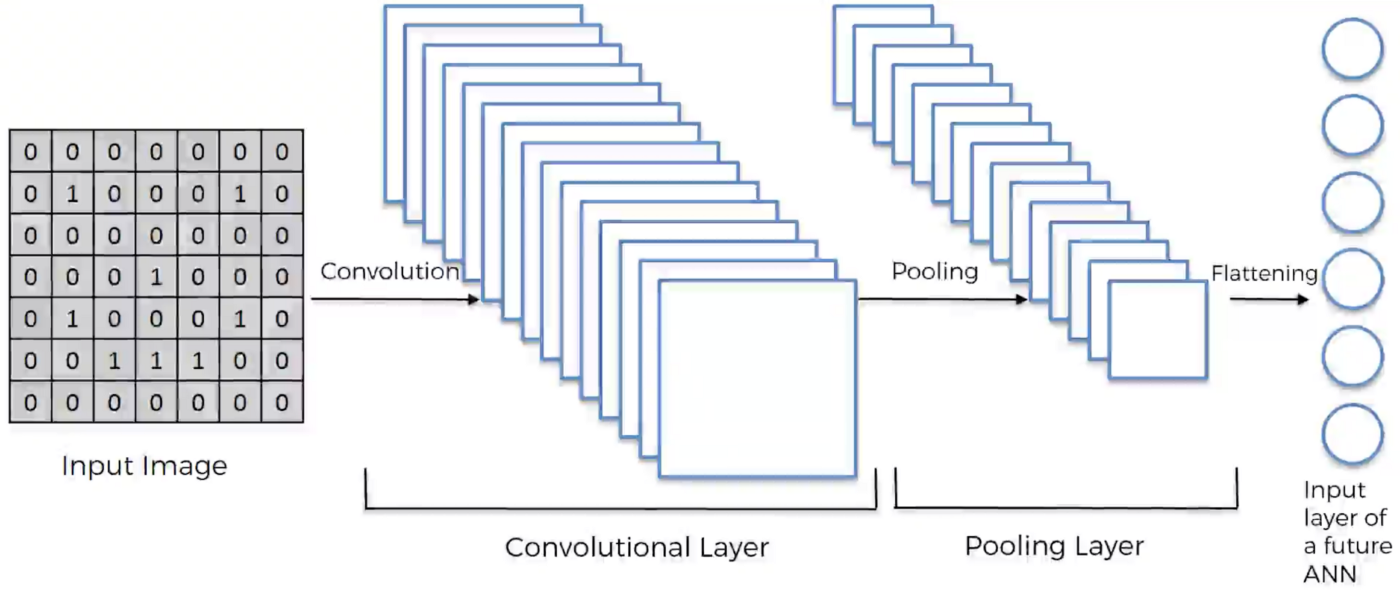
Types of CNN
LeNet
CNN的父親
LeNet的網路架構非常簡單,總共有七層:卷積層、池化層、卷積層、池化層、全連接卷積層、全連接層、Gaussian 連接層
若是想看詳細架構可以跳回5.2小節~
AlexNet
2012年, Prof. Hinton使用AlexNet 在2012年的ImageNet的比賽上拿了冠軍,那時候造成很大的轟動,也使得CNN開始被重視,變成所謂的CNN大時代
AlexNet的網路架構共有八層:五個卷積層與三個全連接層
AlexNet成功的地方有很多:
- 將激活函數從sigmoid改成了ReLu,解決了梯度消失的問題
(若是忘記激活函數的優缺點的話快回去複習一下!!) - 使用maxpooling,而不是meanpooling
- 提出dropout來避免overfitting
- 在資料集中進行資料增量
- 使用兩張GTX580來加速運算
AlexNet也有採用LRN,建立區域性神經元的競爭機制,強化response較大的神經元,抑制response較小的神經元,跨feature map進行normalization,讓資料的差異性更大(不過後來有被證實幫助不大,反而降低準確率)
📌 LRN(Local Response Normalization) 局部響應歸一化:
概念最早是在AlexNet提出,其目的是為了增加訓練的效率,以及提高效度(準確率)。這是一種借鏡人類神經元運作的方式,在被活化的神經元,除了傳遞訊息出去,還會抑制相鄰的神經元。一來一往,傳遞出去的訊息減少了雜訊的干擾,相對被放大。在神經網路裡面,神經單元抑制的可能是同一層的相鄰神經單元,也可以是前後層與之有關連的神經元。這個方式叫側抑制。reference
VGG
當時改善CNN的效能可以從兩個方向著手:
- 使用更小的Conv或是更小的stride
- 利用不同的Data Augmentation,例如: Multiple Scale training等
在VGG中是將兩個合併在一起,提供一個更深且結果穩定的網路
VGG最重要的概念就是使用大量的3 X 3卷積,作者認為將較大的卷積抽換成較小的卷積可以將資訊量提高,且使用較多的較小的卷積比大的卷積可以減少參數
作者認為2X2 pooling可得到更多的資訊量,因此相較AlexNet 3X3 pooling,VGG改用更小的pooling,並不會overlap
📌 Multi Scale Training & Multiple Crop Testing
VGG在training以及testing資料上有做一些不一樣的處理:
- Training的部分使用Multiple scale training,在每次training時,從一個固定的亂數範圍中,random一個數字,並縮放至那個數字,並隨機剪裁成所需大小
- Testing使用多個crop進行預測,將資料rescale成一個大小,並利用固定的crop大小預測左上、右上、左下、右下跟中間,並平均成最後預測結果
Experiments
在VGG的實驗中:
VGGNet 的深度比AlextNet更深,證明Deeper > shallow
從此A vs A-LRN實驗中,可得知加入LRN會降低準確率
在B vs C實驗中,發現若加入1 × 1 Conv,可提高準確度
1 × 1 Conv
把輸入的圖裡面的值做放大或是縮小,感覺沒什麼用,的確沒什麼用,但1 × 1 Conv真的用途重點不是在作卷積這件事情,而是可以拿來做降維或是升維,還可以減少訓練參數
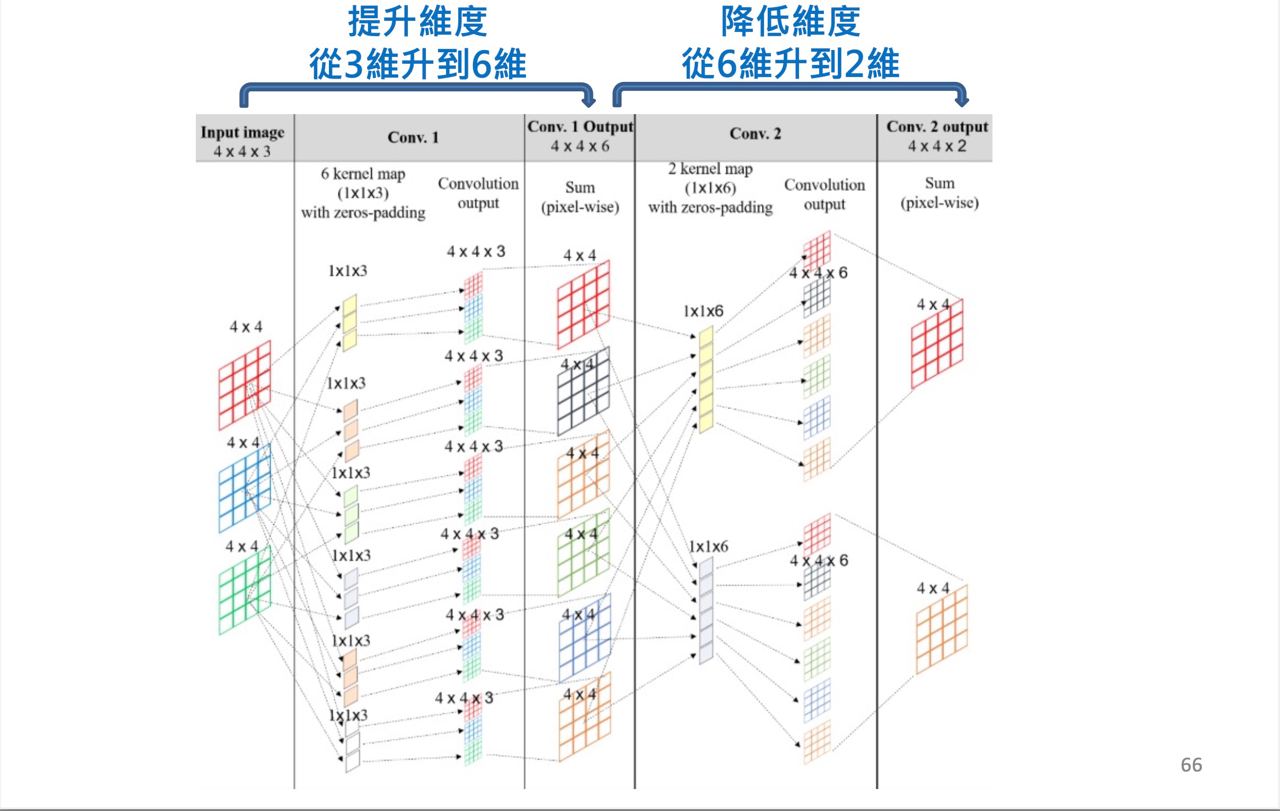
假設input的大小為100x100x56
如果我們做一個有125個filter的5x5卷積層之後(stride=1,pad = 2),輸出將為96x96x125
則參數 : 5655*125 = 175000如果我們先經過28個filter的1x1的卷積,再經過有125個 filter的5x5卷積層之後,輸出一樣為96x96x125
參數 : 561128 + 2855125 = 89068
相對少了快一半的參數在C vs D實驗中作者將1 X 1 Conv替換成3 X 3Conv發現結果更好了,作者解釋為3 X 3 Conv相較於1 X 1 Conv可得到更多的空間資訊量
在D跟E的實驗比較中,發現越深效果不一定越好,需要做更多的Data Augmentaion,才可以讓更多更深的模型學得更好,這是VGG模型的缺陷,當模型越來越深,資料在每一層的耗損越來越高(Ex: Gradient Vanishing),使得在後面幾層就無法學習出好的結果,這個問題在ResNet有被解決,因此RestNet才可以疊出幾百層
最後總結一下:使用較小的Conv或使model變深可得到較好的準確度,LRN對模型較無太大的幫助~
GoogleNet
在GoogleNet中提出的新架構 - Inception模組,因此GoogleNet又被稱為“Inception Network”
Filter size往往不知道要設定多少,因此GoogleNet在網路中結合不同的filter來解決filter設定的問題(先通過1 x 1 Conv來達到降維和減少參數),也移除了全連接網路,直接連結softmax(參數數量是AlexNet的一半),因此GoogleNet可以更好的控制參數
ResNet
若是網路越多層 => “以訛傳訛” => 如果傳的人越多 => 錯誤率越高,導致退化問題(Degradationproblem),也會更容易造成梯度消失的問題
因此在ResNet中加入捷徑來解決這個問題,解決退化問題,使得深度學習網路真正可行
What does CNN learn ?
- Every filter is used to detect different texture such as “|”, “/”, “\”……..
- Every filter only consider the small vison of the image
- Neuron considers the whole image
- The image to activate a neuron is not like a small texture. Should be more complex => Becomes a pattern
Assume that the output of the k-th filter is a 11 x 11 matrix.
CNN needs to find an image maximizing the output of neuron, each figure corresponds to a neuron
Deepdream
Initially it was invented to help scientists and engineers to see what a deep neural network is seeing when it is looking in a given image.
Later the algorithm has become a new form of psychedelic and abstract art

CNN Application
- Alpha GO
- Speech
- Text
- YOLO