Recurrent Neural Network 文章筆記整理
1102 機器學習
這篇文章是學習時整理的一些筆記,讓自己複習時方便,文章部分內容為上課之內容及閱讀清單之整理
本篇文章內容均是說明RNN,若是還沒看過NN介紹的建議從deep learning 相關文章開始閱讀喔!!
CNN 文章筆記整理Introduction
在deep learning該文中有提到不同的Neural Network有他不同的擅長領域,像是CNN擅長處理影像,而RNN擅長處理與時間序列有關之資料或是自然語言處理
我們今天要穿什麼?
這個問題可以透過模型進行預測嗎? 是可以的
不過先前我們介紹的模型都不太適合拿來預測這個問題
因為當你在決定今天要穿什麼衣服上課時,你不僅僅只會考慮當下的情況,你還會考慮「昨天穿過什麼?」甚至是「這禮拜我穿過了哪些?」來決定今天要穿什麼衣服,怕有重複
這樣的話那我們就必須要記住我們昨天穿了什麼或是這禮拜都穿了什麼
RNN就被專門設計來解決時間相關問題的神經網路~
他主要是透過將隱藏層的output存在Memory裡,當下次input資料進去train的時候,會同時考慮上一次存在Memory裡的值進行計算
這樣說RNN領域好像還是有點抽象
除了上面例子以外,RNN擅長做自然語言處理
每一個詞語的意思不能單看那個詞本身的含義,有時候也會因為上下文不同而意思也略有不同
- Position of words is important
- Slightly change a word may change meaning of whole sentence.
- Lack of sequence concept in ordinary NN.
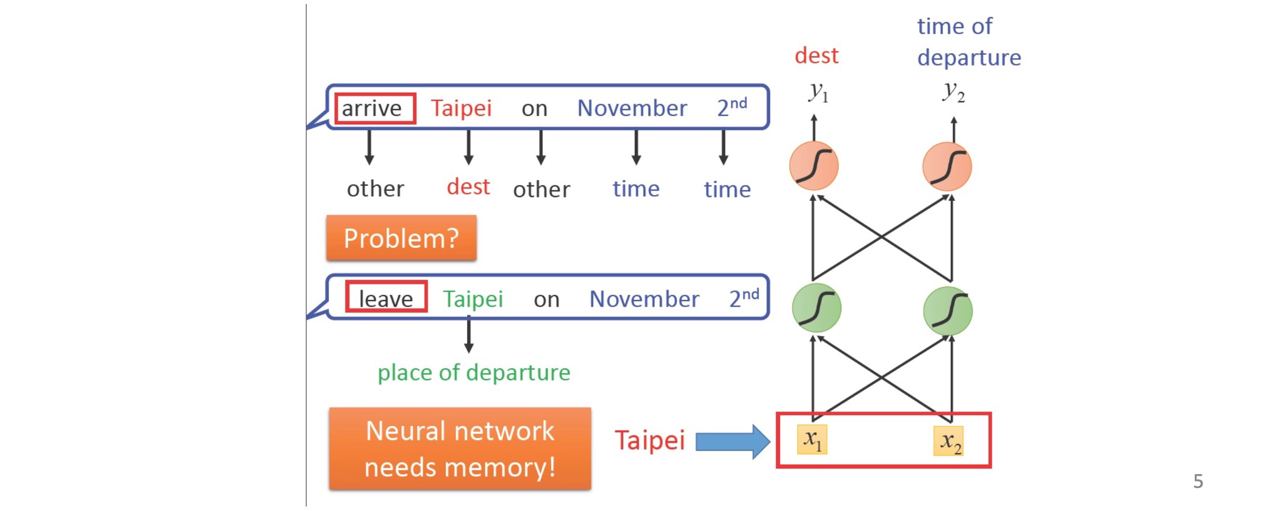
=> Memory is important
memory 在網路中是什麼概念呢?
再舉一個加減乘除運算的例子好了
當我們在運算 144 + 177 = 321時
在直式的加法當中,我們的「進位」可以視為是我們要記住的東西,如下面那張圖
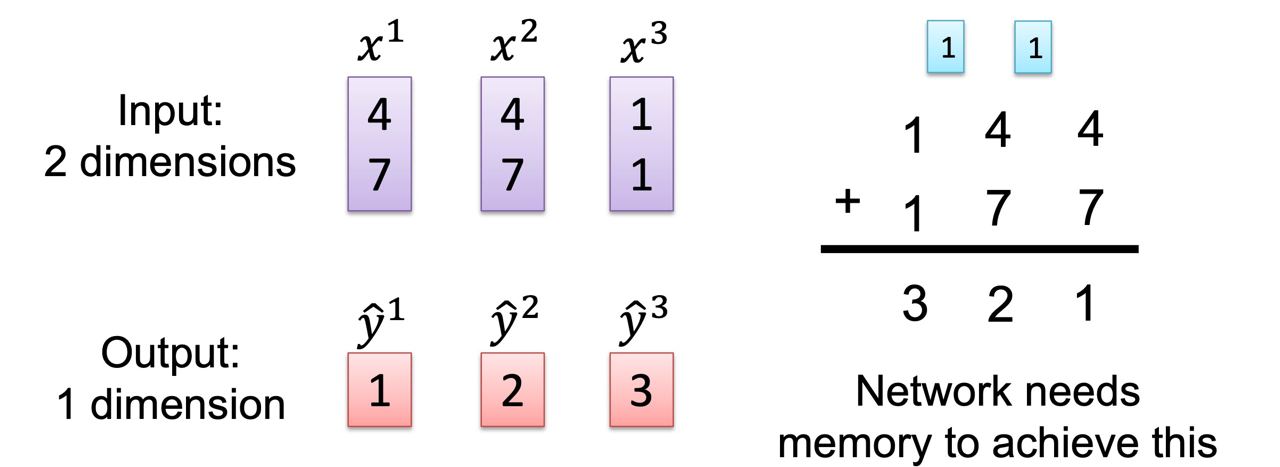
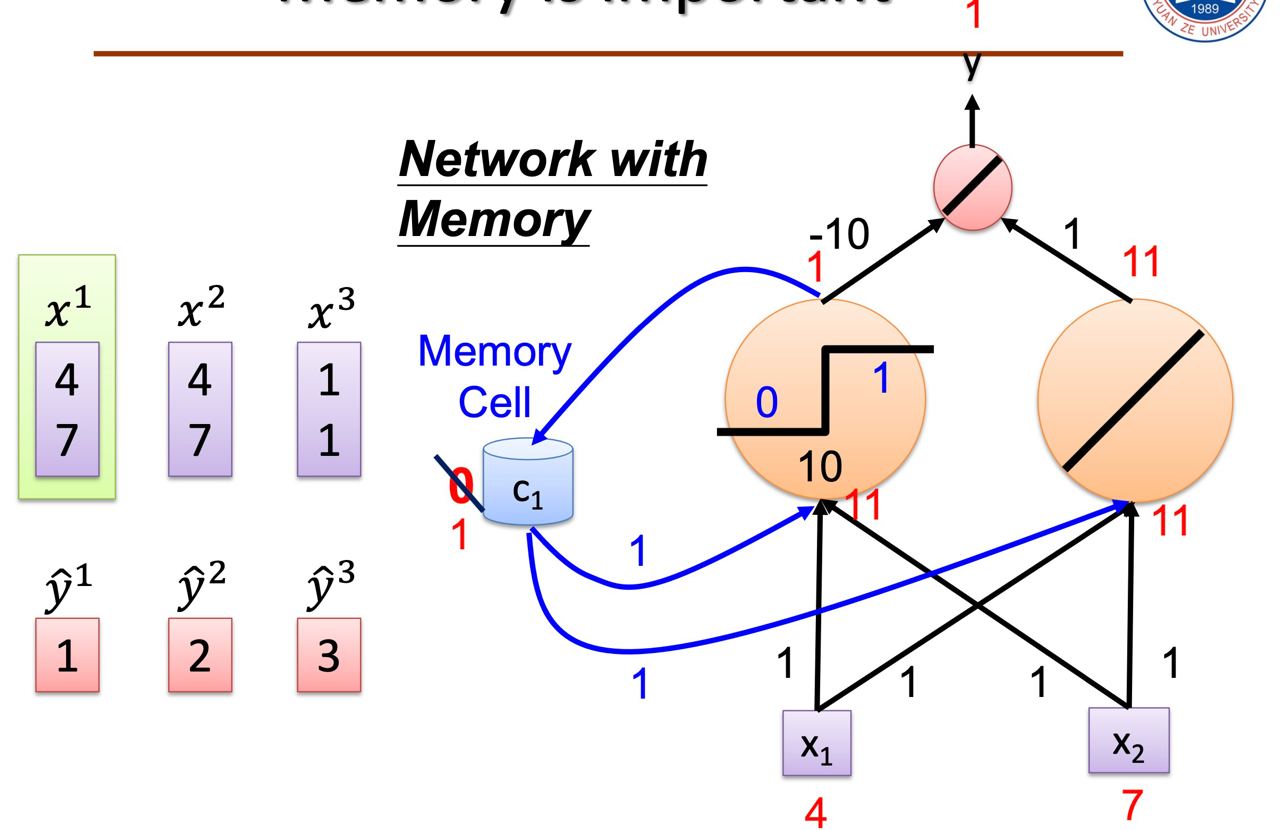
當我們把它以neuron的形式來表示時,就會長成這樣:
RNN model
因此RNN的model會長這樣
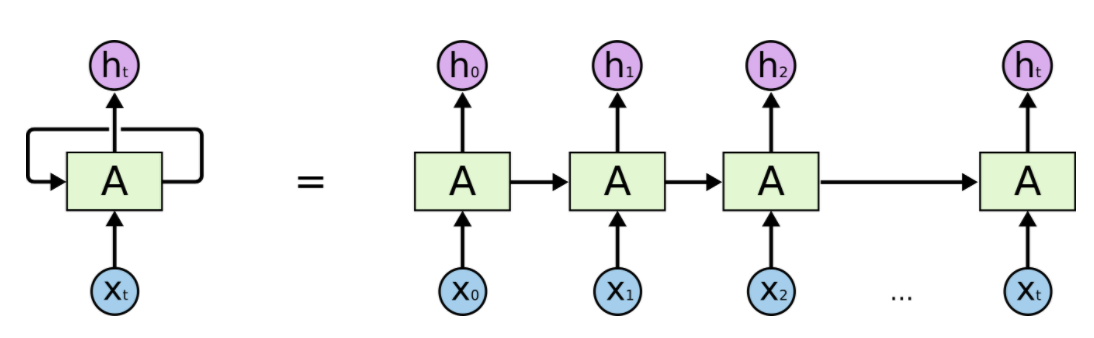
上圖是一個簡化版RNN的示意圖
我們先看左邊部分:
神經網路為A,xt為某個時間(狀態)的輸入,然後輸出一個值ht
透過循環可以把信息從當前時間點傳遞到下一個時間點
這些循環使得RNN可以被看作同一網路在不同時間步的多次循環,每個神經元會把結果傳給下一個時間
而把它展開後,就會變成右邊的樣子
- Input and output are vector sequences with the same length
- The same network is used again and again
- Backpropagation through time (BPTT)
- RNN Training is very difficult in practice
Types of RNN
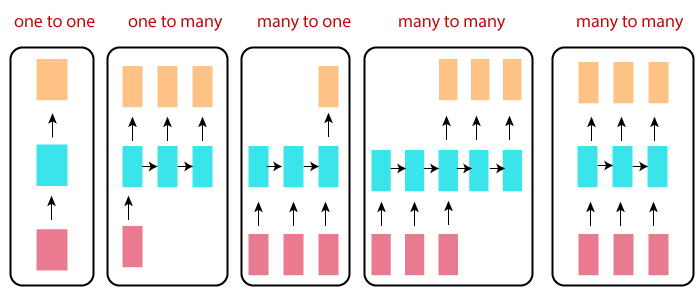
依據 input 及 output 的數目,RNN 可以有很多的變化與應用
1. 一對一(one to one):固定長度的輸入(input)及輸出(output),即一般的 Neural Network 模型。
2. 一對多(one to many):單一輸入、多個輸出,例如影像標題(Image Captioning),輸入一個影像,希望偵測影像內多個物體,並一一給予標題,這稱之為『Sequence output』。
3. 多對一(many to one):多個輸入、單一輸出,例如情緒分析(Sentiment Analysis),輸入一大段話,判斷這段話是正面或負面的情緒表達,這稱之為『Sequence input』。
4. 多對多(many to many):多個輸入、多個輸出,例如語言翻譯(Machine Translation),輸入一段英文句子,翻譯成中文,這稱之為『Sequence input and sequence output 』。
5. 另一種多對多(many to many):『同步』(Synchronize)的多個輸入、多個輸出,例如視訊分類(Video Classification),輸入一段影片,希望為每一幀(Frame)產生一個標題,這稱之為『Synced sequence input and output』。
reference
One-hot encoding
在繼續之前,我們先來介紹一下什麼是One-hot encoding
獨熱編碼,又稱為一位有效編碼
他的方法是使用N位狀態暫存器來表示N個狀態
每個狀態都有它獨立位子,並且在任意時候,其中只有一位有效
舉個例字來說
今天有貓狗豬三類,而貓是第一類以此類推
那我們要怎麼表示[狗, 貓, 豬]這個串列呢?
那就是[010, 100, 001]
這樣就有了解「每個狀態都有它獨立位子,並且在任意時候,其中只有一位有效」代表的是什麼了吧!
因為只會有一個答案,像是貓,就是會是貓,不會是狗也不會是豬,因此他只會在第一個位置是1,其他都是0
再舉個例子,也可以用於文字表達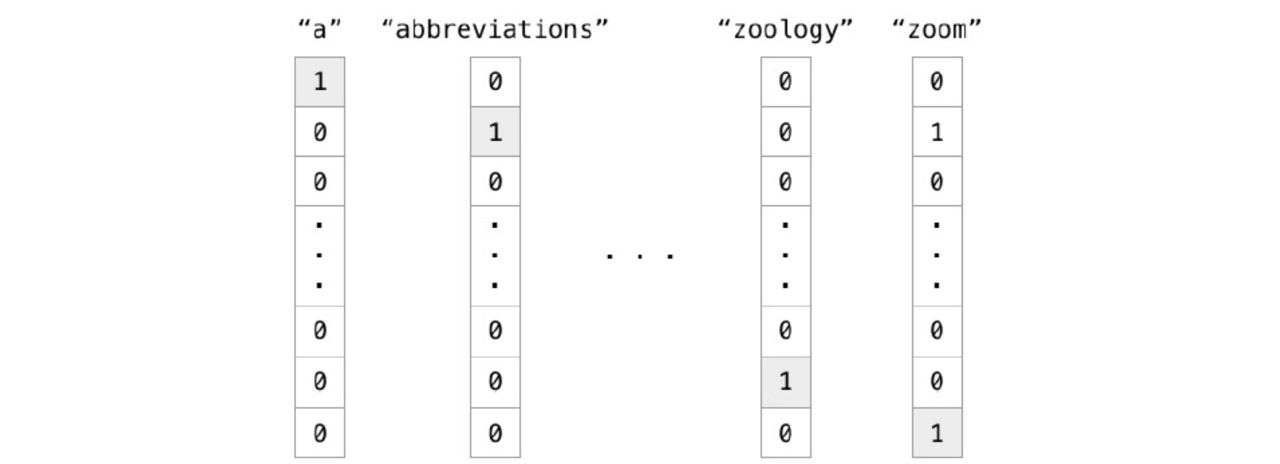
We let machine read a lot of articles and use one hot encoding on each word
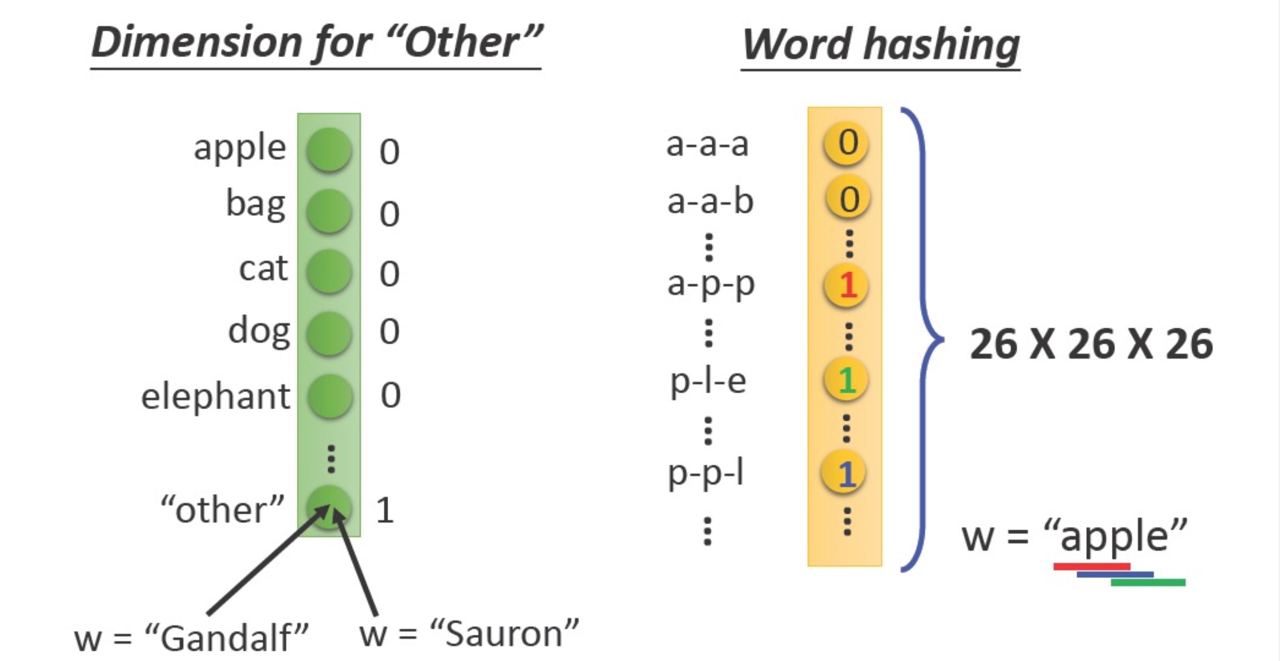
而我們這樣做的好處主要有可以解決了分類器不好處理屬性資料的問題,也可以在一定程度上也起到了擴充特徵的作用
不過他也是有缺點的:
- Dog is not close to cat
Machine can not understand the meaning of word. - Waste a lot of entity
Most of entity are zero
Dimension of vector = vocabulary size (very large)
Gradient explosion & vanish
雖然目前講的都很理想,不過回到現實,RNN存在著很大的問題,那就是梯度消失與梯度爆炸
這個問題導致了RNN非常難訓練,因此後來衍伸出了很多變形,例如:LSTM
若想看更多RNN梯度消失詳細推導建議閱讀👉RNN梯度消失和爆炸的原因
這樣會導致哪些問題呢?
因為是back propagation,因此梯度消失會導致該層網絡以前的權重無法得到更新,無法更新,也就是意味著停止了學習
而在循環神經網路中,梯度爆炸會讓我們的學習不穩定,參數變化太大也就不容易優化了,沒辦法很好的學習,也就不容易訓練
Backpropagation through time
在了解BPTT之前,若是不知道Back propagation是什麼的建議先了解一下喔~
Back Propagation 是什麼?這裡只簡述一下BPTT是什麼,不會推導,如果要看詳述的話建議前往這裡
RNN所使用的演算法方法並不是像DNN一樣的,而是進階版本的BPTT,BP不同的地方就在於BPTT是透過時間來進行訓練的,因此很容易梯度消失
梯度消失是一種在訓練的時候因為梯度歸零而發現訓練沒有效果的情況
至於為什麼要用時間呢?
因為神經元會透過Memory記憶的值在權重已經被固定的情況下,得出與時間相關的對應答案。所以其實Memory記憶的值和應該出現的答案之間的關係是需要被訓練的,這就是為什麼我們需要透過時間來進行訓練
那爲什麼容易出現梯度消失問題呢?
因為歷史資訊太長了
首先,梯度消失是因為對參數連續進行偏微分而導致數值爆炸性的縮小。你可以簡單想像是係數相乘而導致數值不斷趨近於零。
比方說,我們有那經典的一句To be or not to be, that’s the question.。很顯然,單字的出現是一個時間相關問題(次序相關)。那麼我們應該可以用RNN來訓練。
但是如果想要學習單字跟單字之間的關係並沒有那麼容易,只是To跟be大概沒什麼問題,我們使用反向傳播訓練,只要對歷史資訊偏微分一次就可以找到他們在歷史資訊上的相關性。
但是To跟question呢?反向傳播法會需要連續的進行偏微分來找到To跟question之間的關係,但連續的偏微分就會導致梯度消失,這讓我們很難找到他們之間的關係。
所以在對歷史資訊做反向傳播法的時候,很容易會遇到很嚴重的梯度消失問題,你壓根沒辦法讓神經元透過hidden state的變化來找出應該有的輸出。
那怎麼辦呢?這裡要出動我們的救星LSTM和GRU。
reference
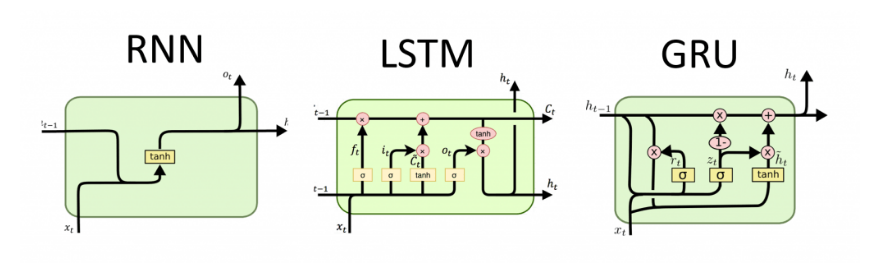
LSTM
LSTM比起原來的Memory ,他多了三個gate,分別是Input gate, Forget gate, Output gate
- Input gate: 決定這一次的輸入需不需要被記憶,或者要記多少(可能只有記個三成)
- Forget gate: 決定要不要遺忘之前的hidden state,也可以按比例遺忘
- Outout gate: 決定這一次所得到的輸出要放多少(也是比例)進去hidden state小房間。
這三個門的合作可以讓某些不重要單字被忽略,讓梯度可以順利進行遠距離的傳遞
由於hidden state來自三個門的線性運算,這讓hidden state與歷史資訊之間呈現線性而非乘積的關係,避免了梯度消失
No Gradient vanishing(If forget gate is opened.)
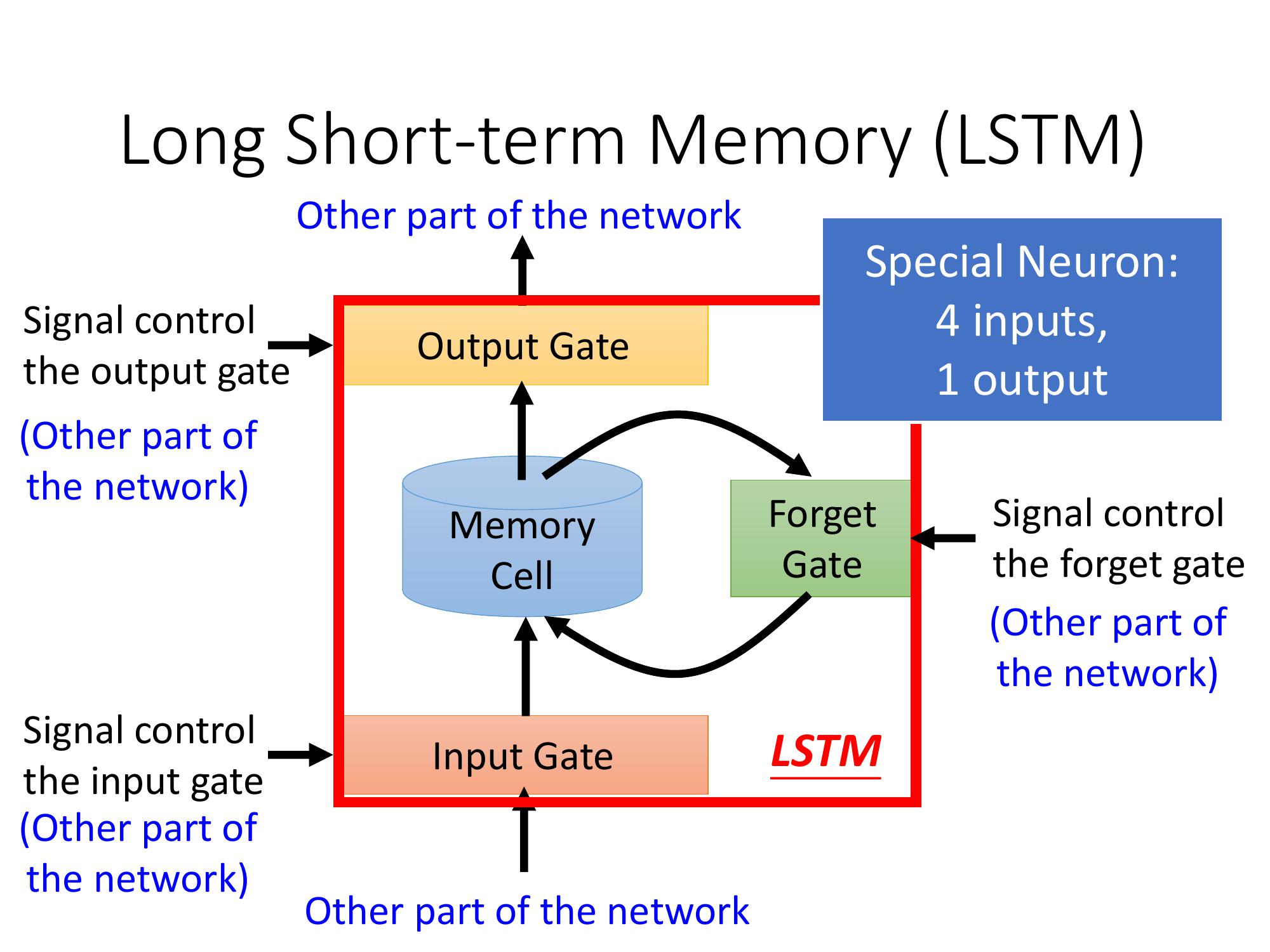
- Activation function f is usually a sigmoid function
- Sigmoid function between 0 and 1
- Mimic open and close gate
GRU
GRU有兩個門,Reset Gate和Update Gate。
- Reset Gate: 決定是否要遺忘之前留下來的hidden state
- Update Gate: 決定這一次的hidden state所要留下來的比例
所以GRU也是透過兩個門之間的線性運算來產生hidden state,進而避免了梯度消失
Gated Recurrent Unit(GRU): simpler than LSTM. Training is more robust than LSTM.
- SimplifyLSTM
Onlytwogate(reset,update gate) - parameters are fewer than LSTM – Prevent overfitting
Inputgateandforgetgateare linked. - When there is new input, forget the older value.
Summary